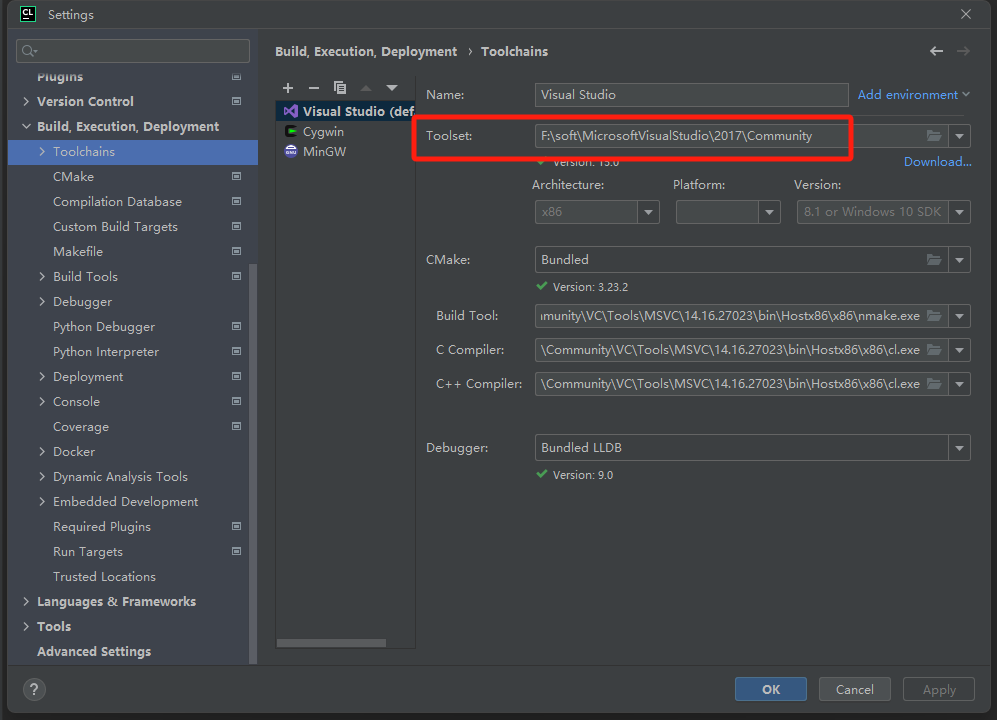
nginx源码编译并调试,nginx源码使用GDB或者vscode+GDB远程debug源码调试-图文详细
克隆项目
1 | git clone https://github.com/nginx/nginx.git |
进入目录下
1 | cd /home/hou/nginx |
生成配置
1 | auto/configure --prefix=./bin --with-debug --with-cc-opt='-O0 -g' |
--with-debug
作用:启用 Nginx 的调试日志功能。
解释:
启用后,Nginx 会输出更详细的调试信息到错误日志中(
error_log)。这些信息对于排查问题非常有用,例如请求处理流程、模块加载情况等。
需要在 Nginx 配置文件中设置日志级别为
debug:1
error_log /path/to/error.log debug;
--with-cc-opt='-O0 -g'
- 作用:向 C 编译器(如 GCC)传递额外的编译选项。
- 解释:
-O0:禁用编译器优化。-O0表示不进行任何优化,保留所有调试信息,方便调试。- 如果使用
-O2或-O3,编译器会优化代码,可能会影响调试(例如变量被优化掉,无法查看)。
-g:生成调试信息。- 在编译时生成调试符号,这些符号会被 GDB 等调试工具使用。
- 如果没有
-g,GDB 将无法显示源代码和变量信息。
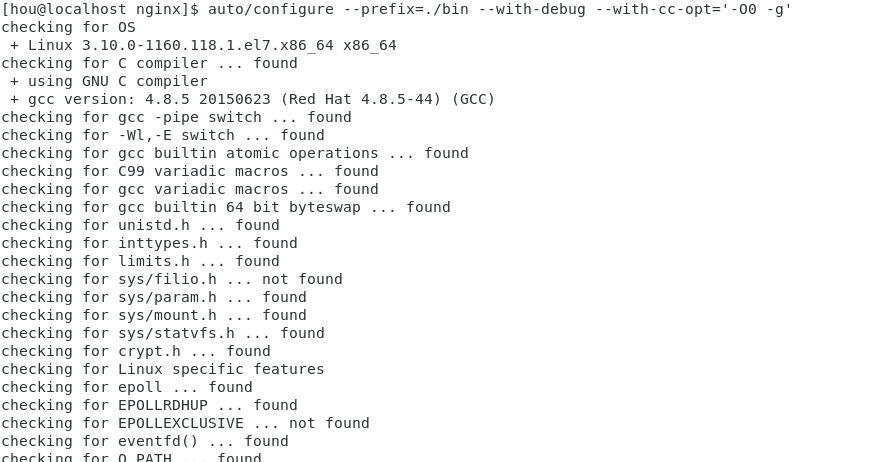
生成成功
编译
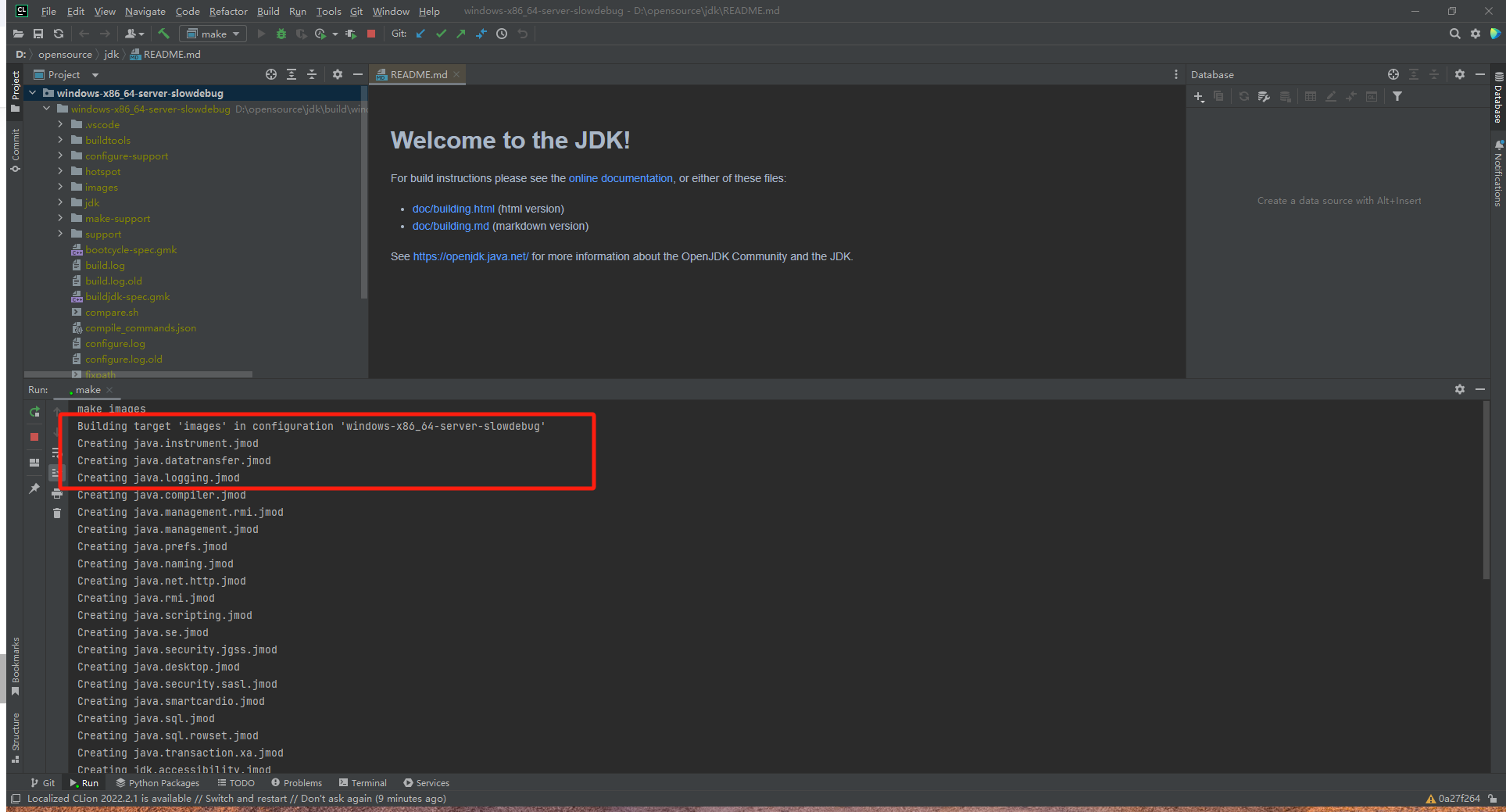
1 | make |

生成成功
安装
1 | make install |

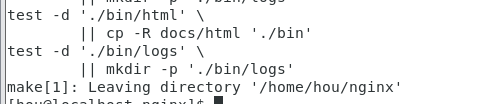
可以看到已经生成成功

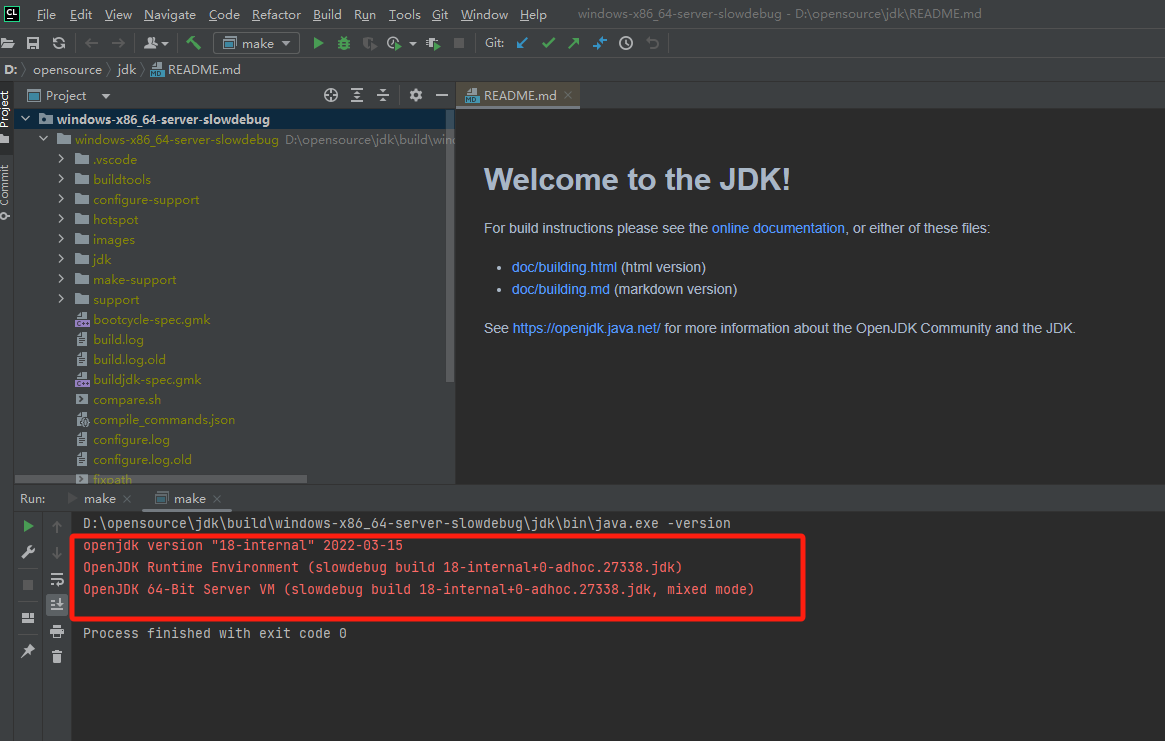
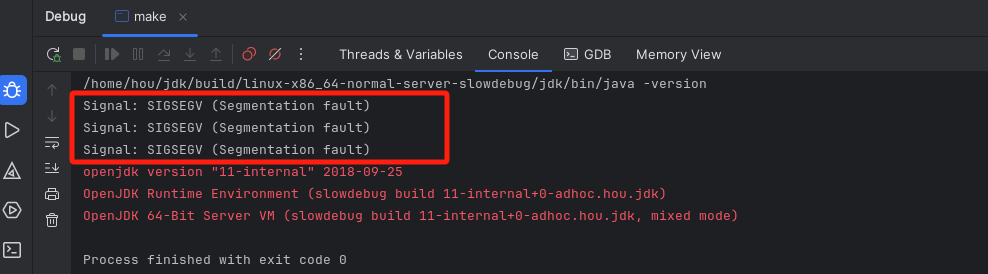
测试
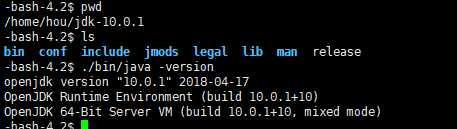
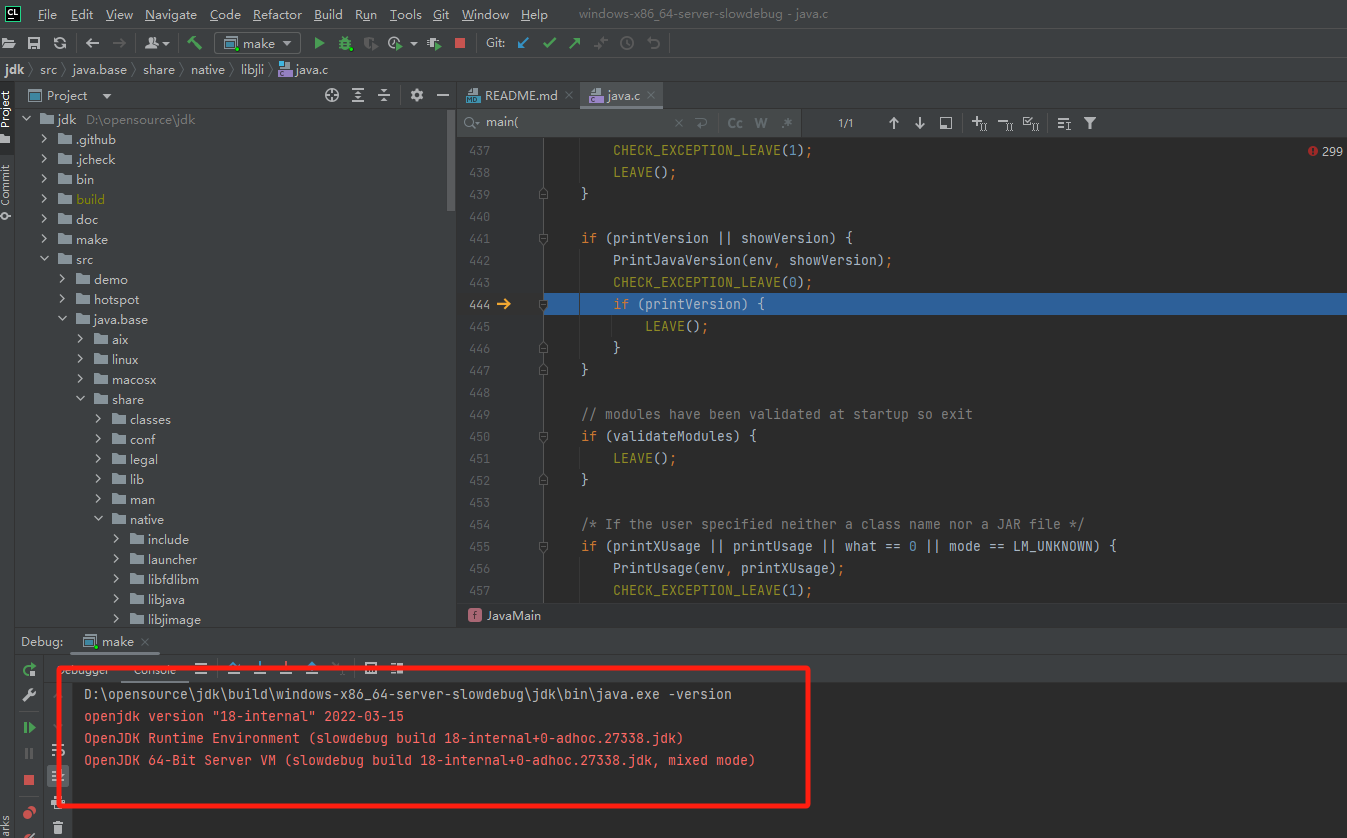
查看版本
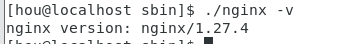
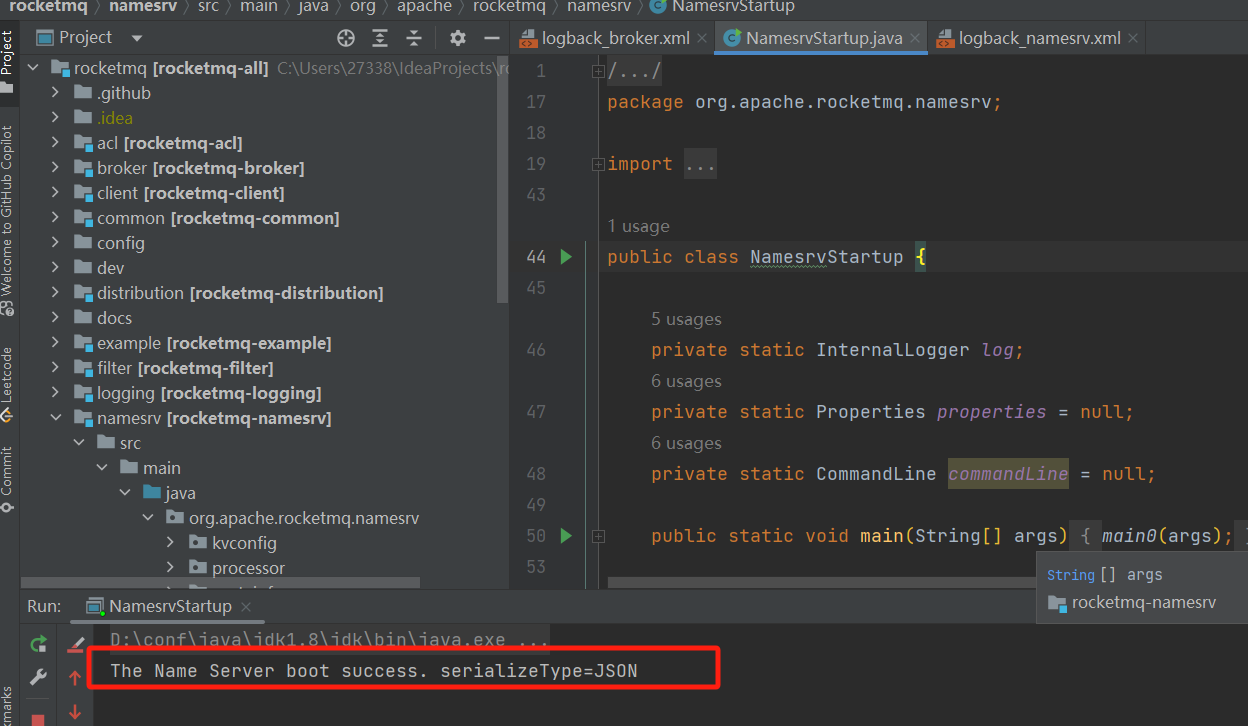
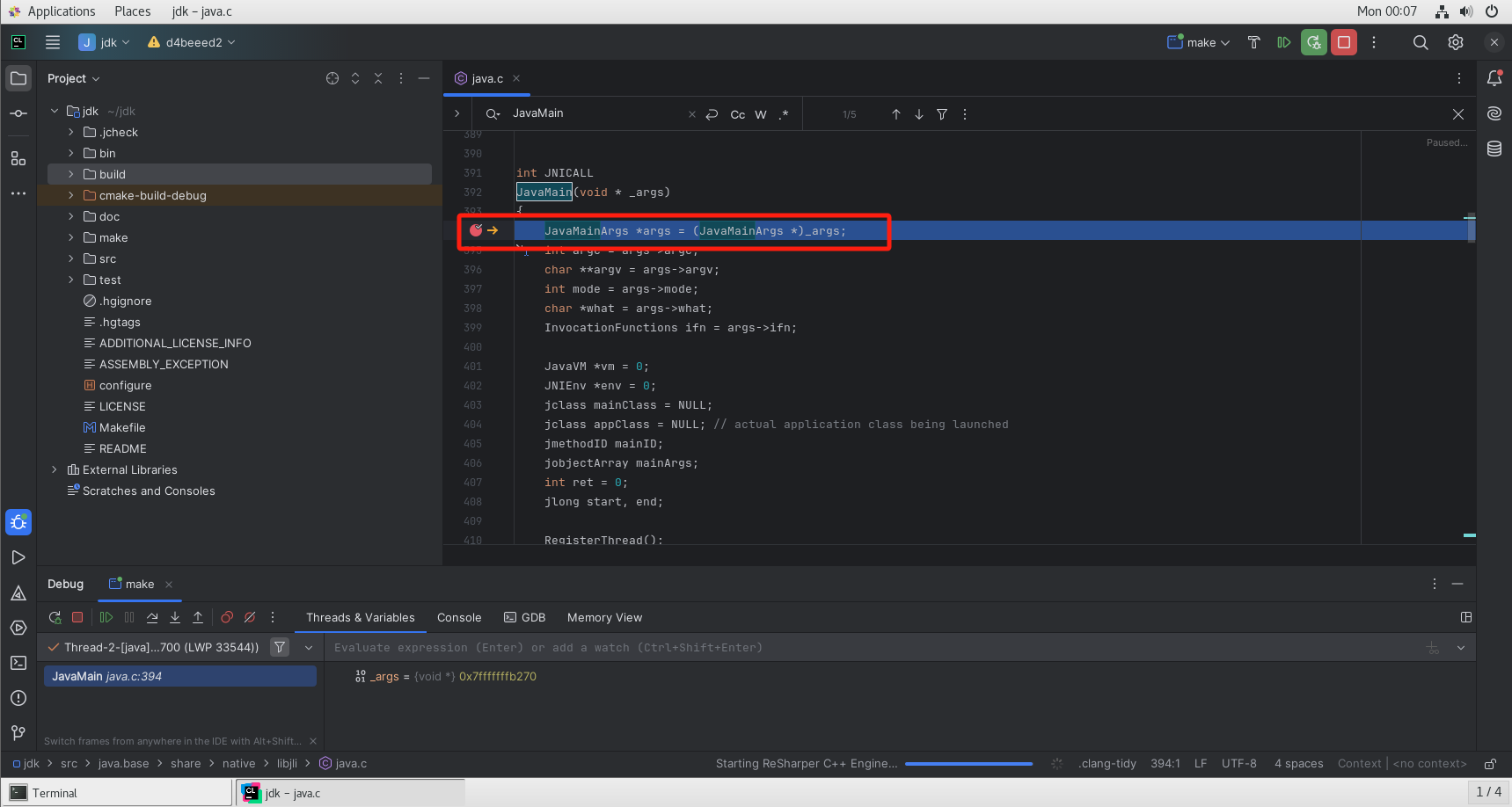
GDB调试
1 | gdb ./nginx |
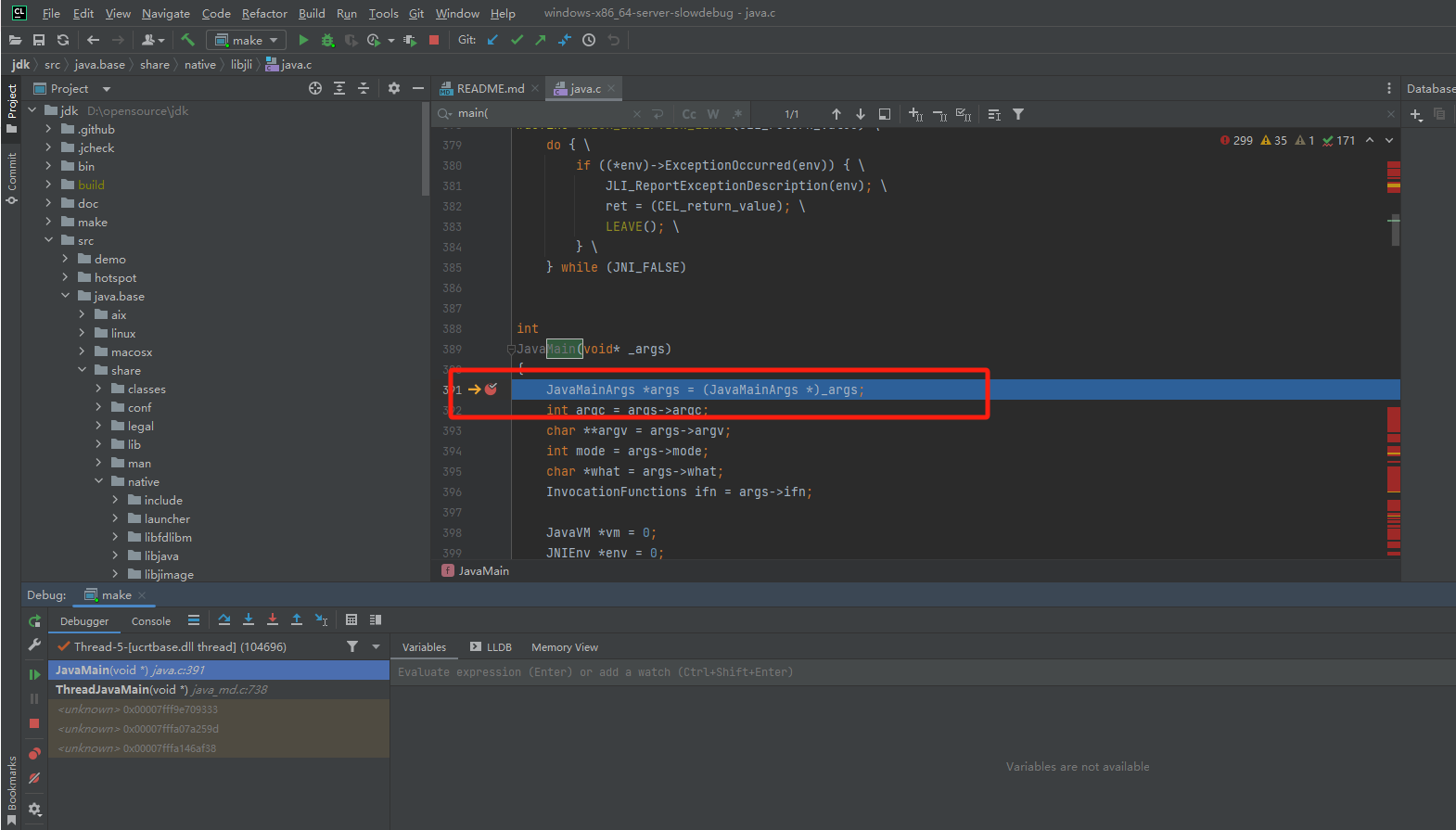
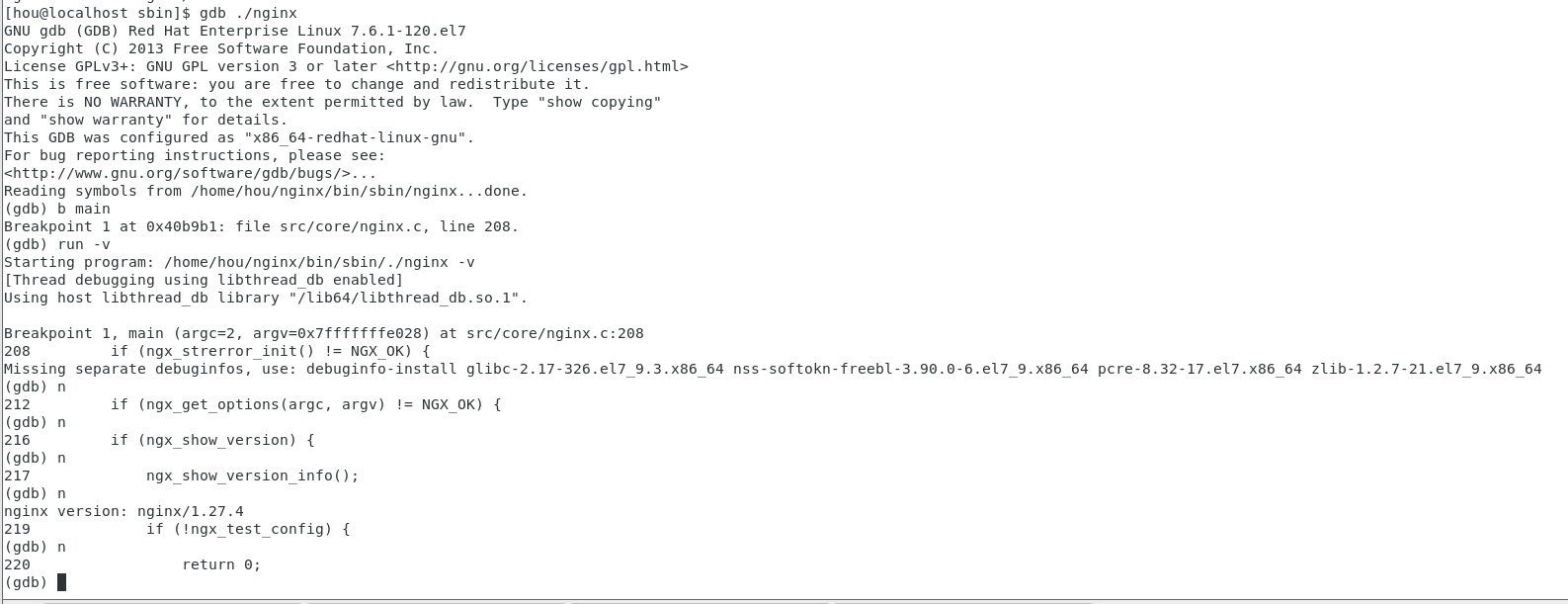
设置断点
1 | b main |
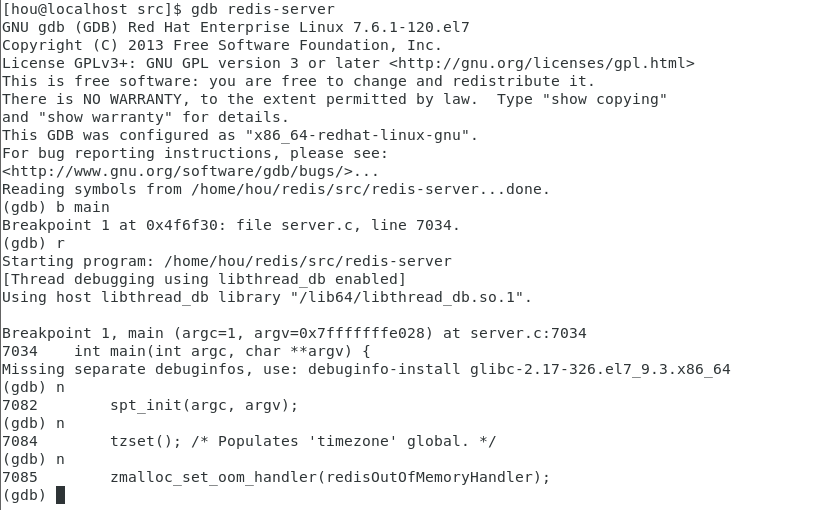
执行打印版本号
1 | run -v |
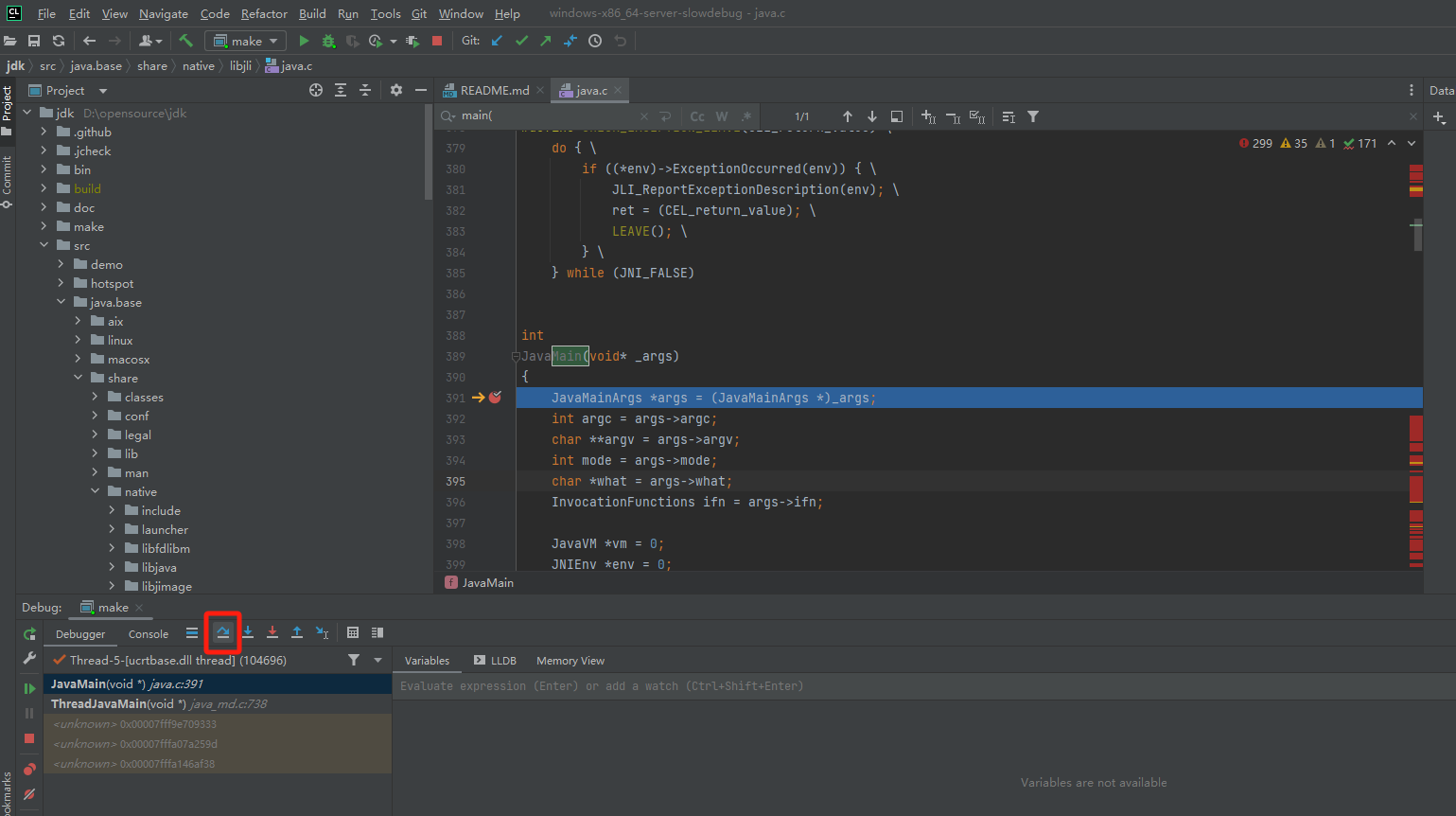
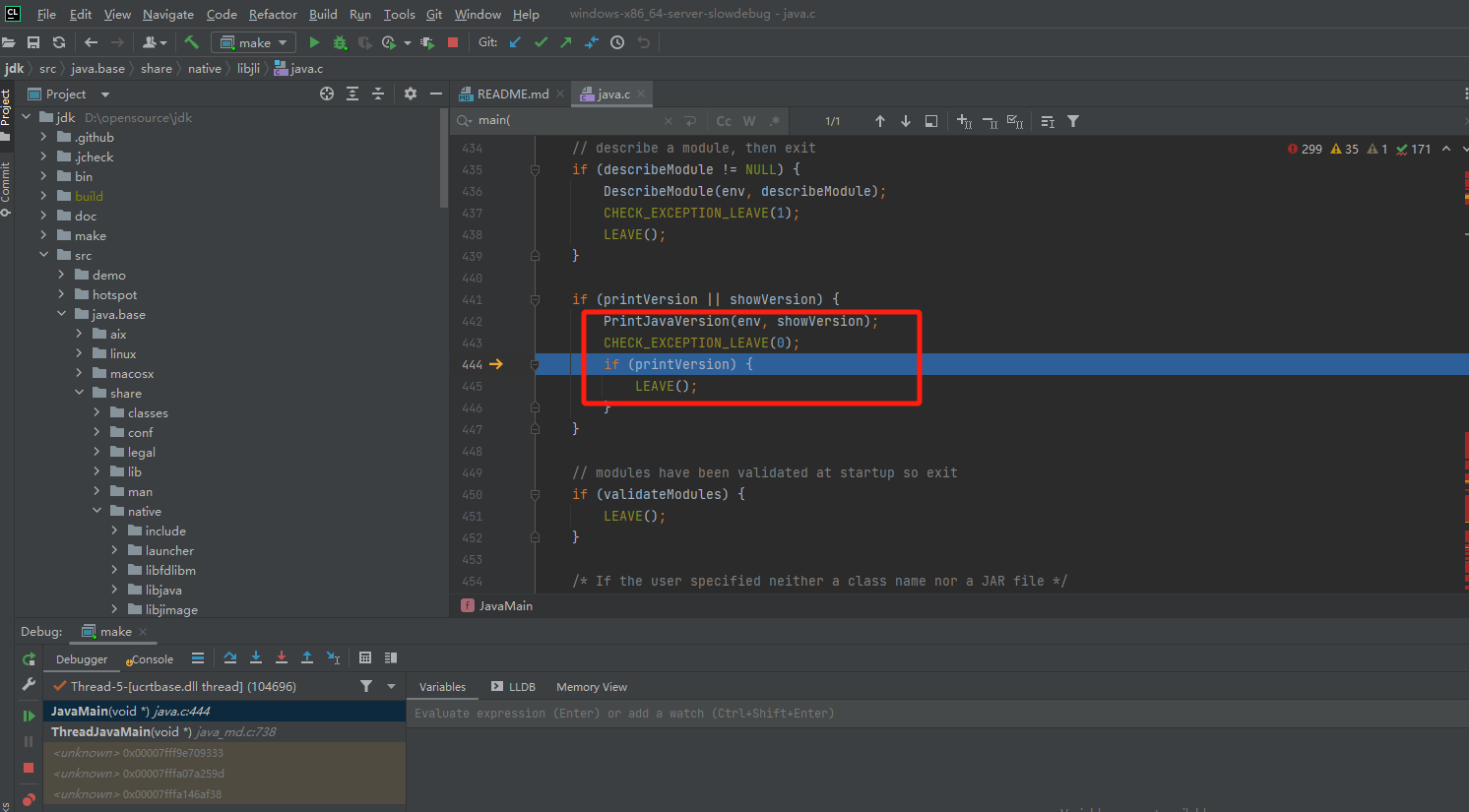
单步调试
1 | b |
退出
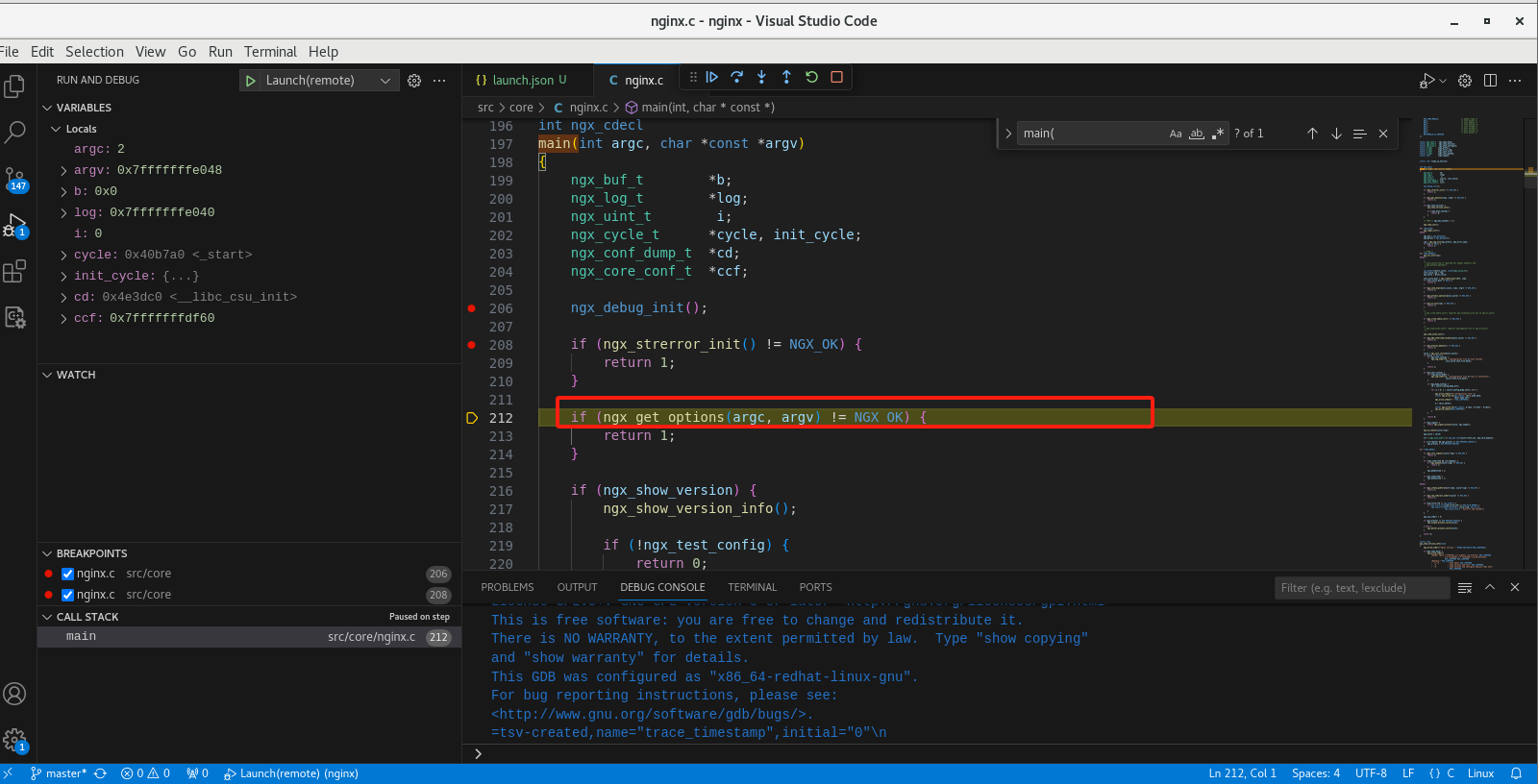
vscode+GDB调试
借助开源免费工具调试,一个字爽,不在受license的干扰。
安装code
https://code.visualstudio.com/updates/v1_85
安装好后启动
输入code就可以启动
1 | code |
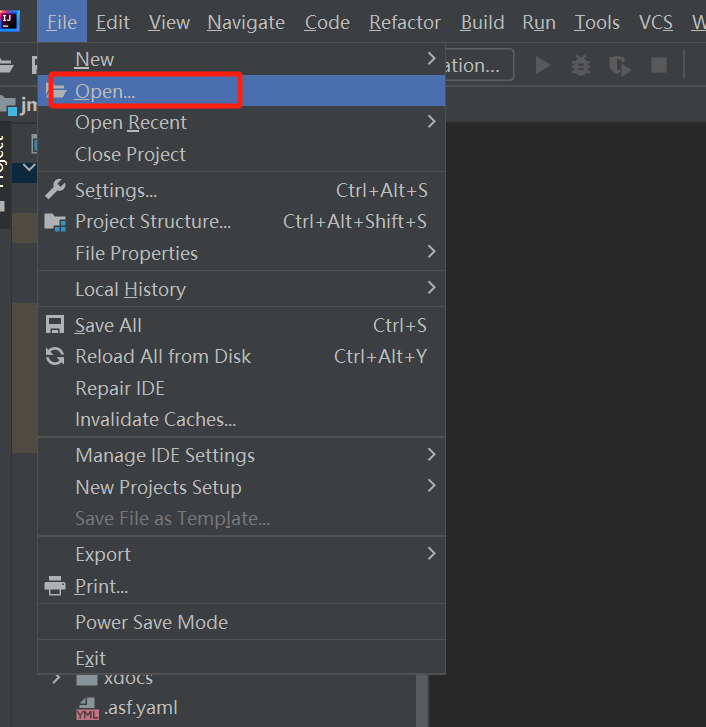
打开源码目录
安装插件
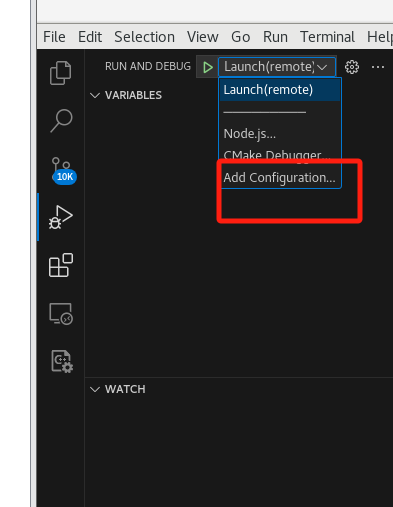
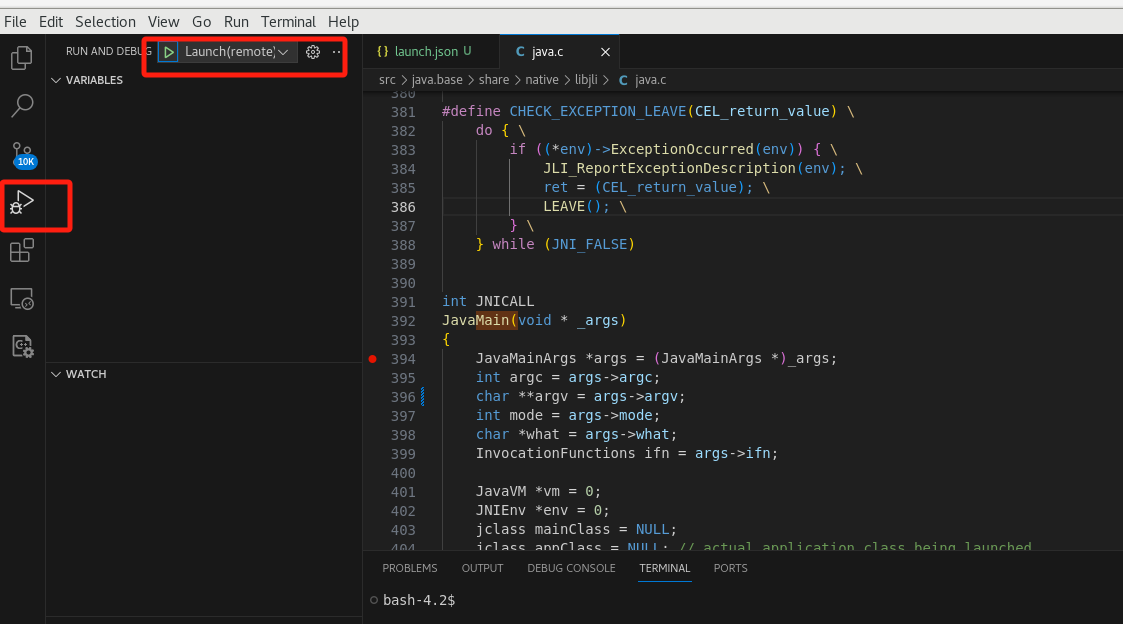
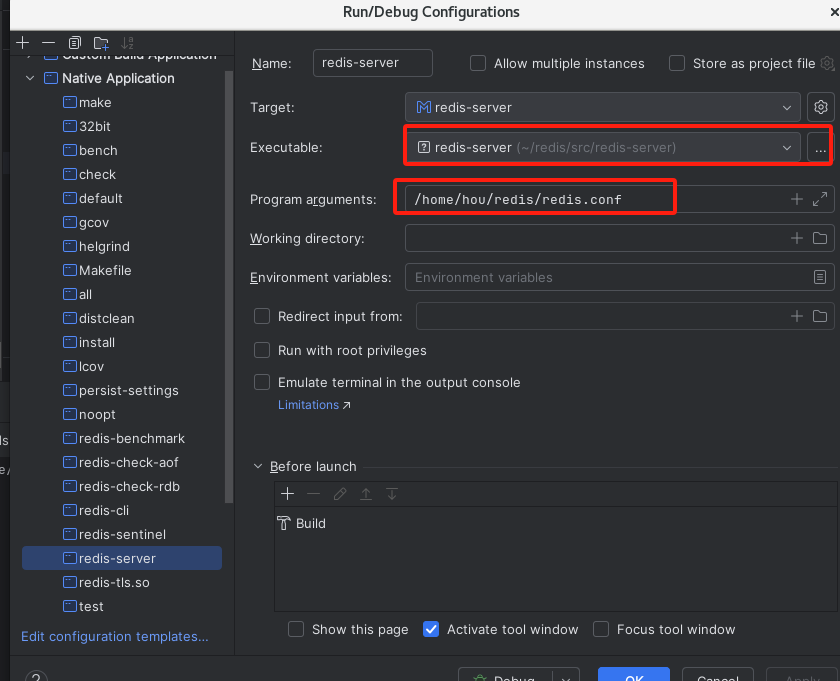
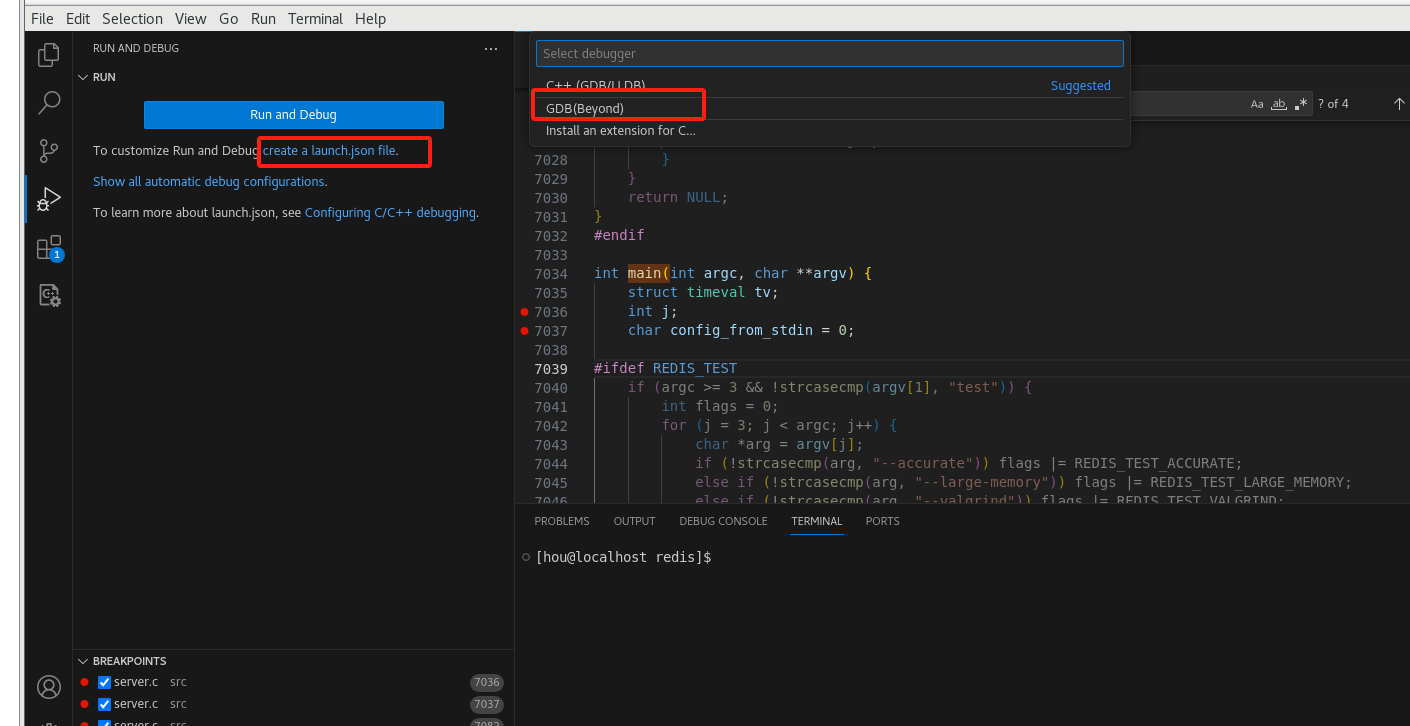
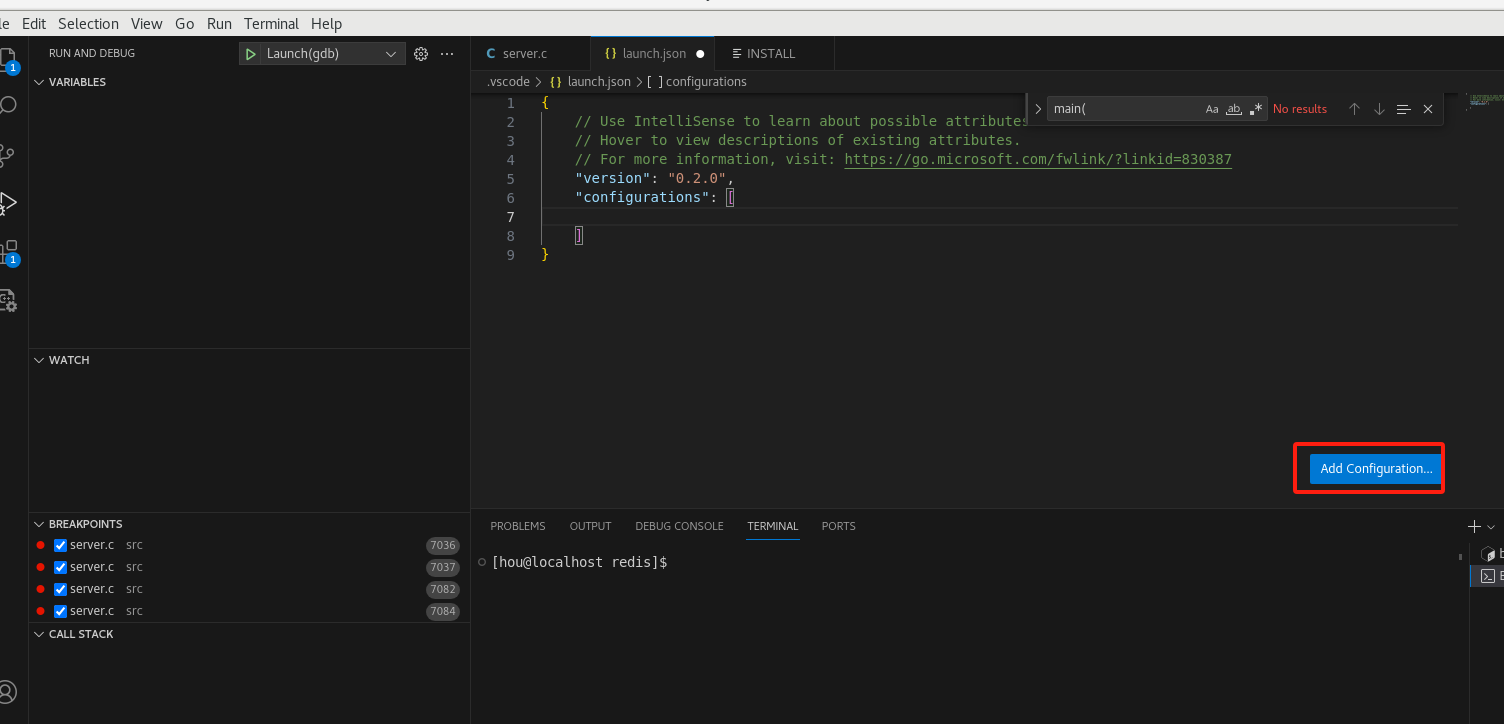
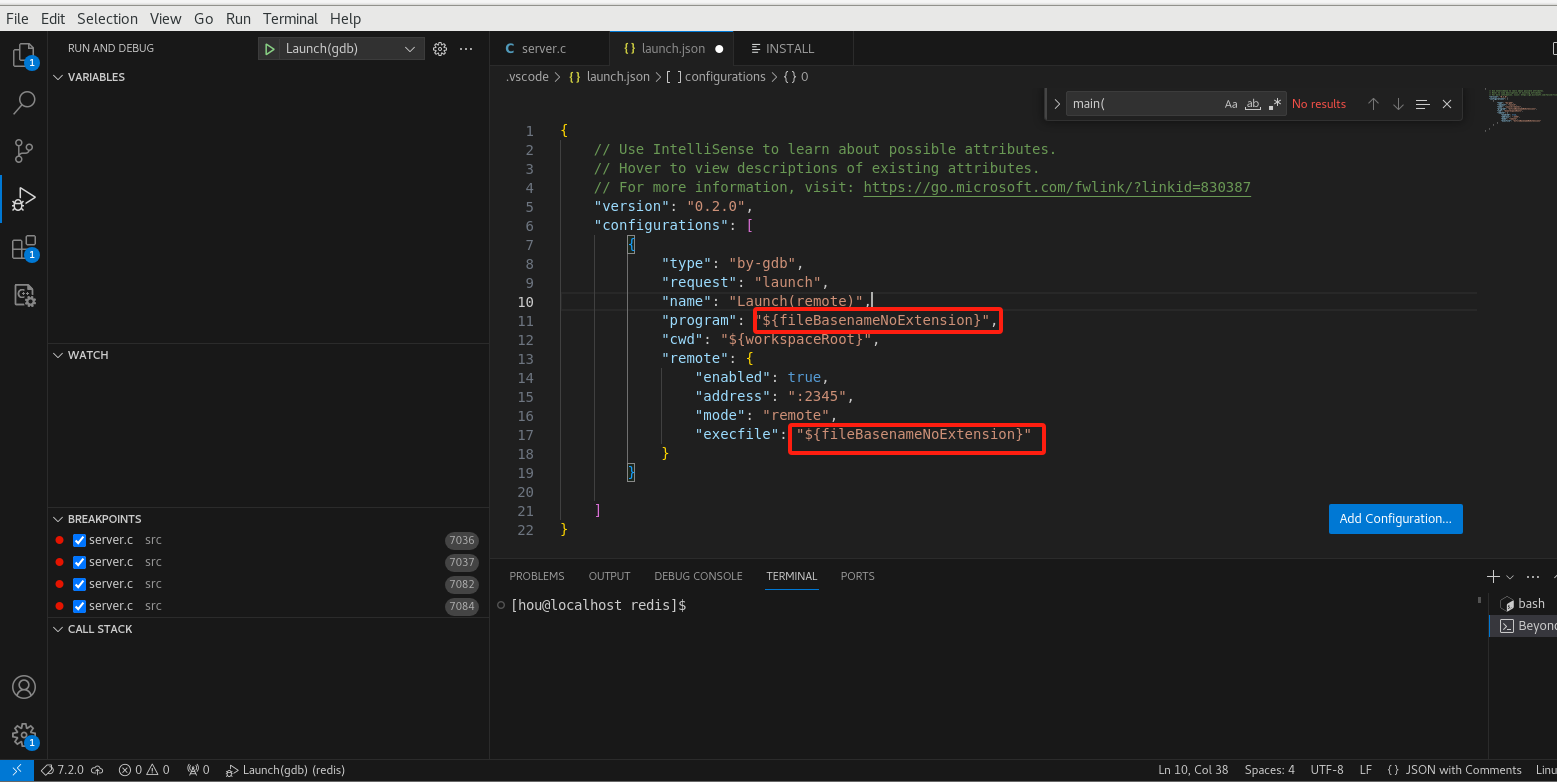
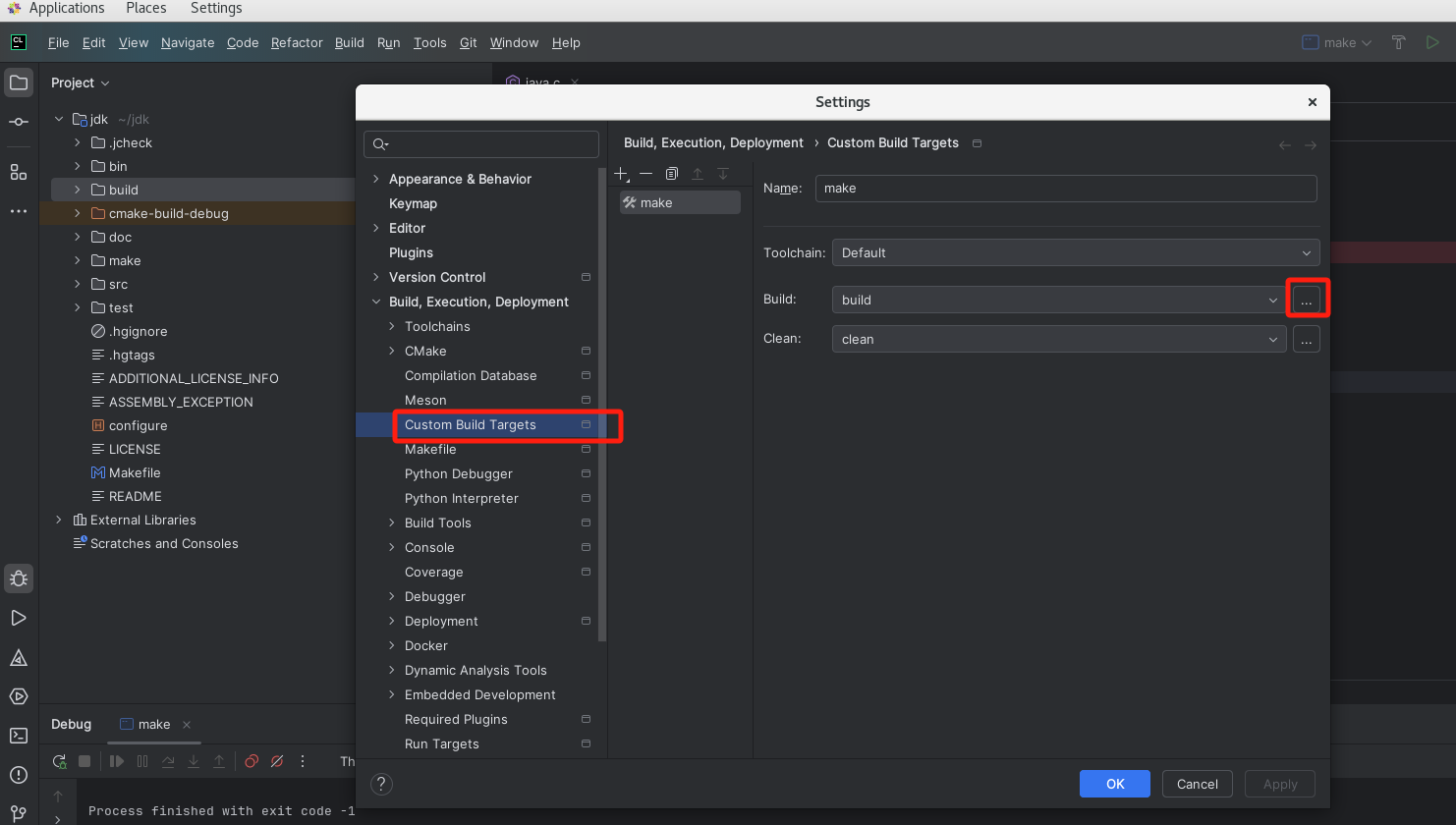
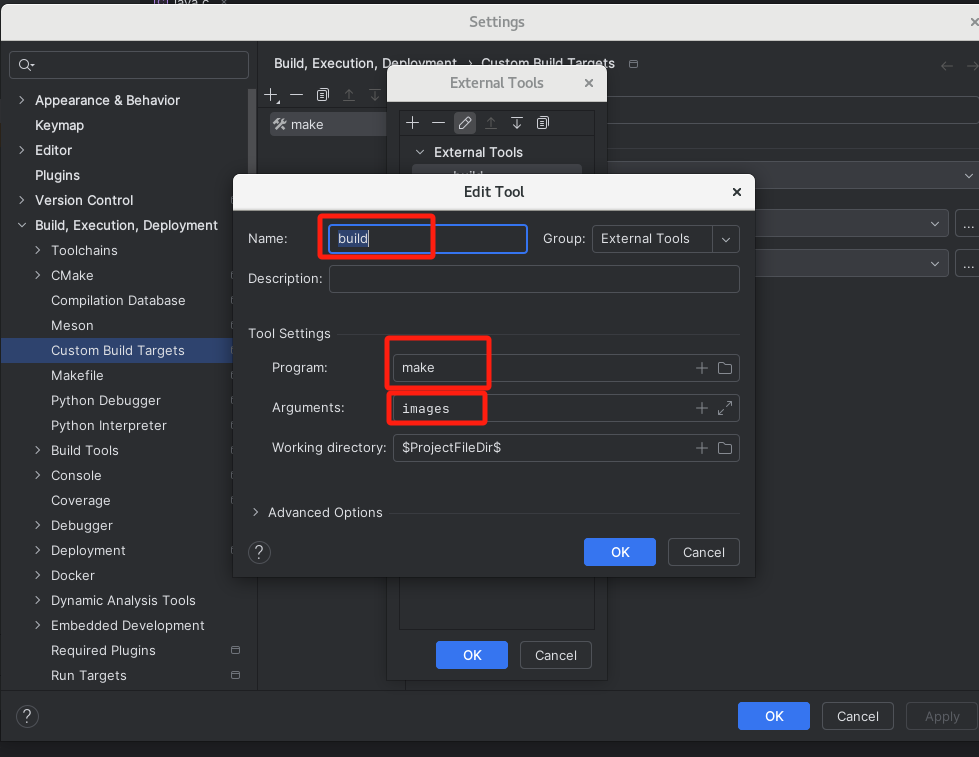
添加配置
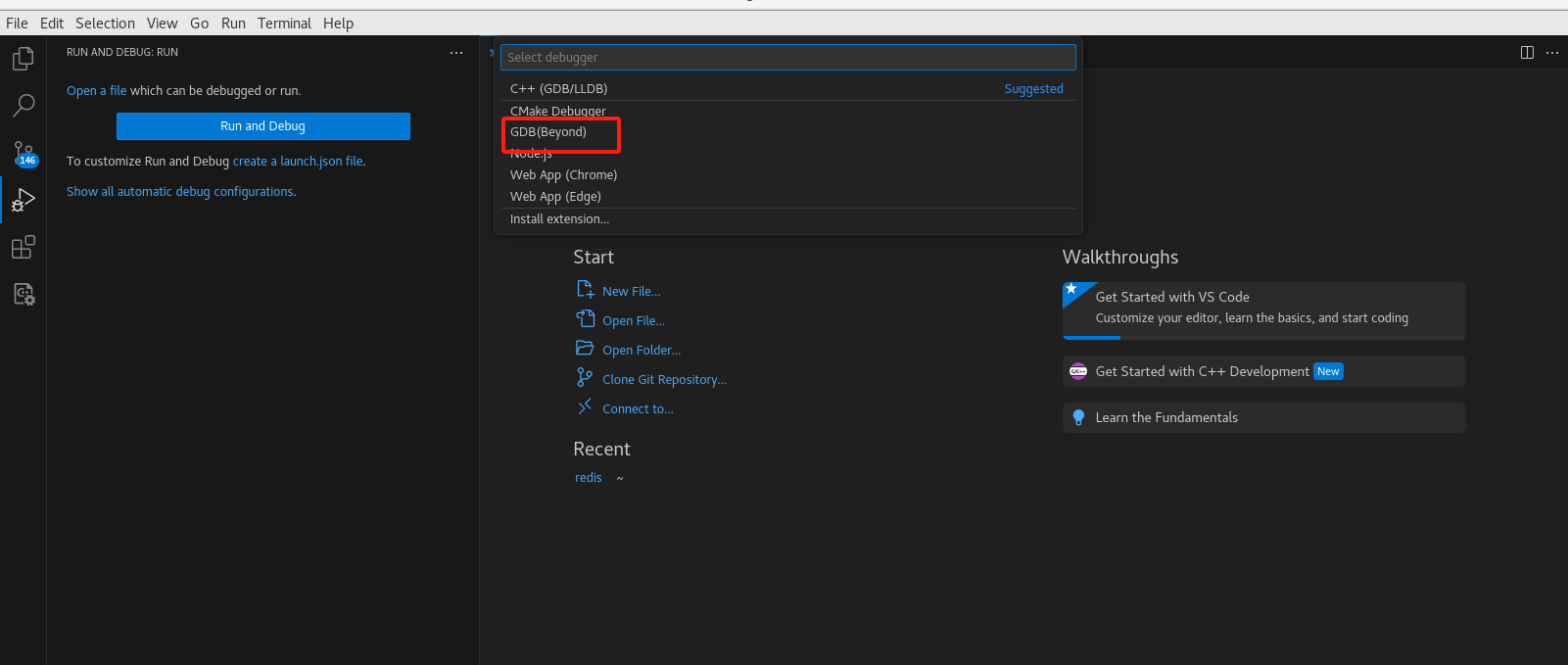
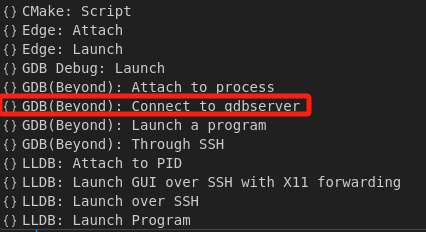
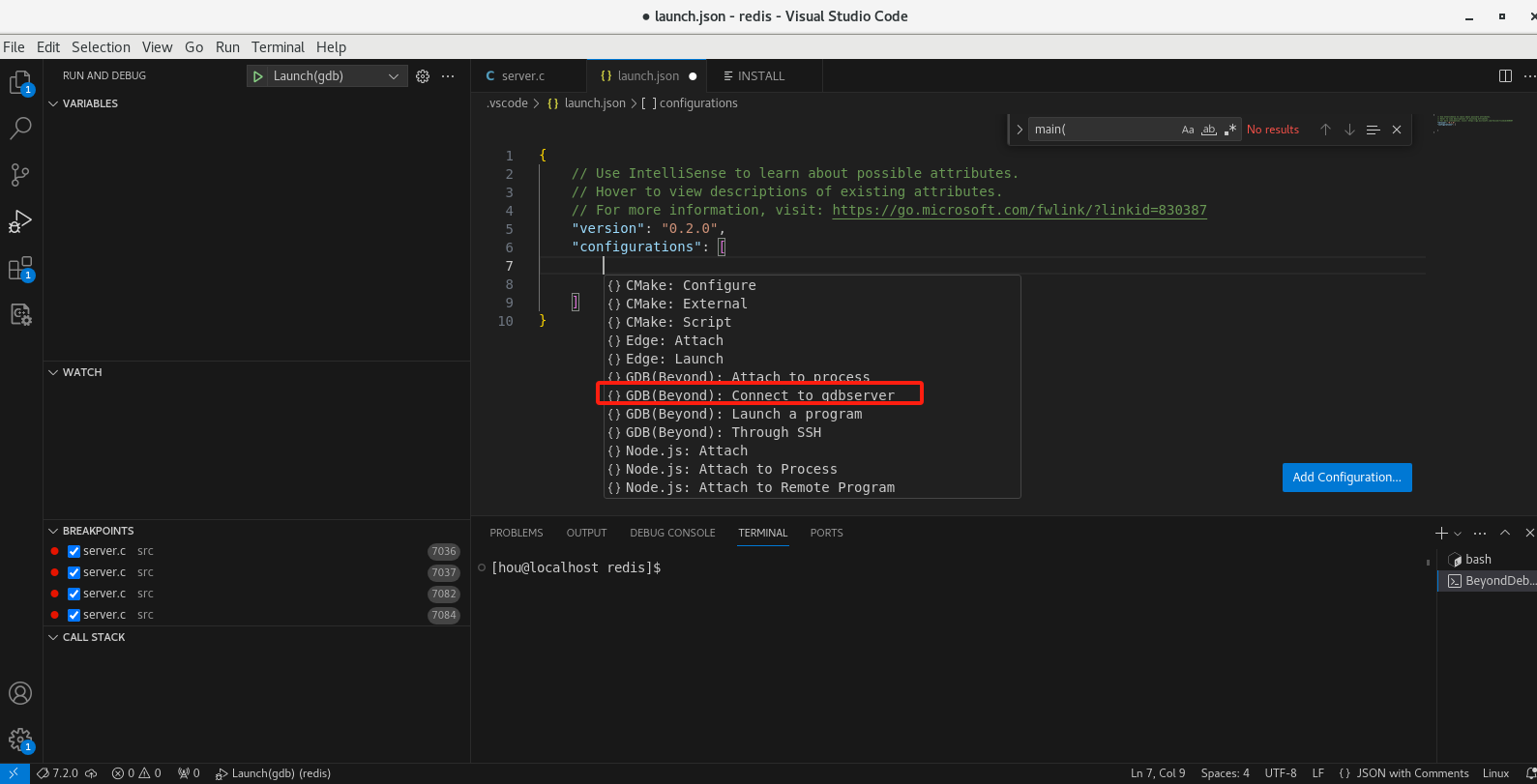
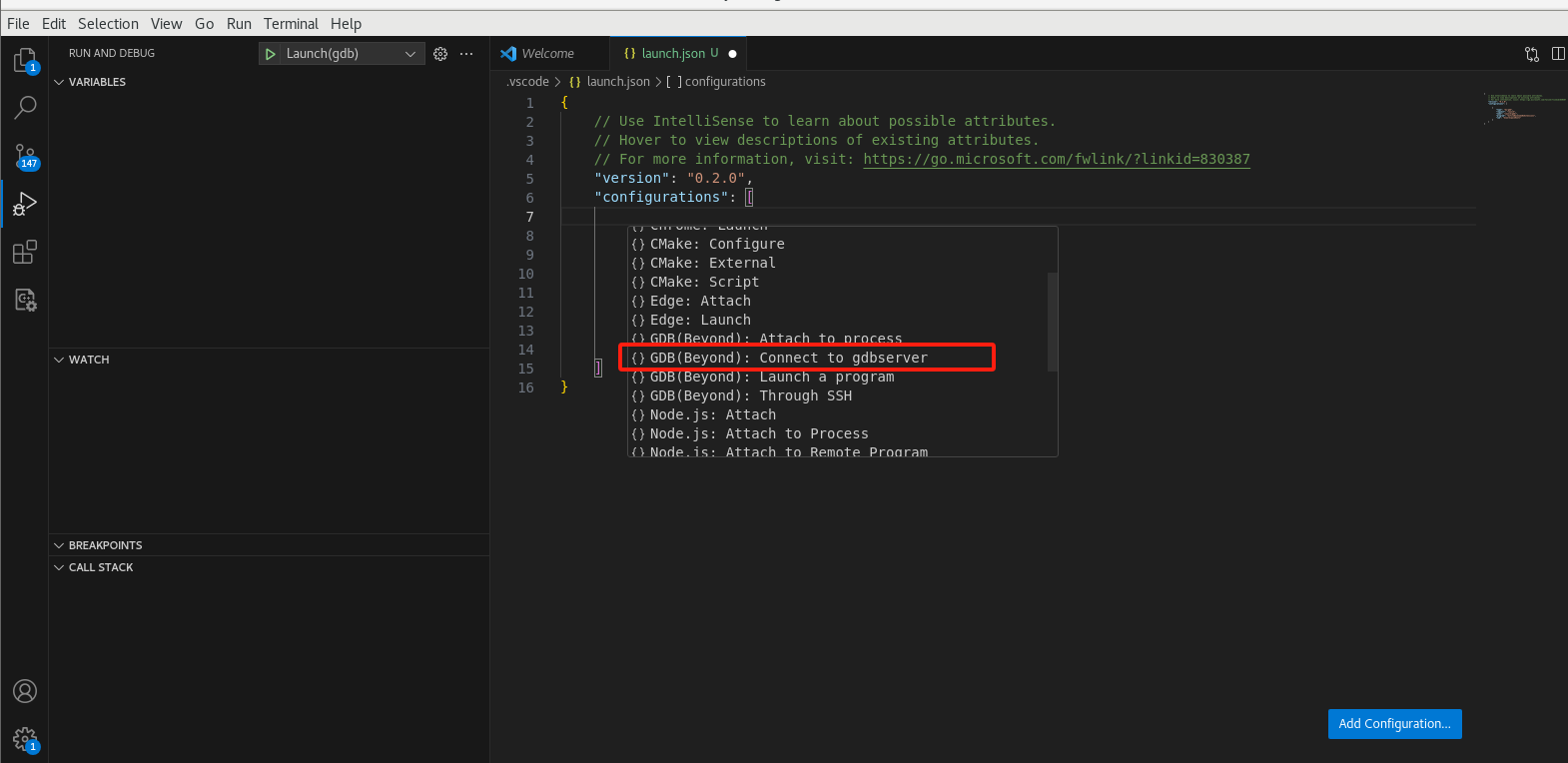
添加配置文件选择连接远程gdbserver
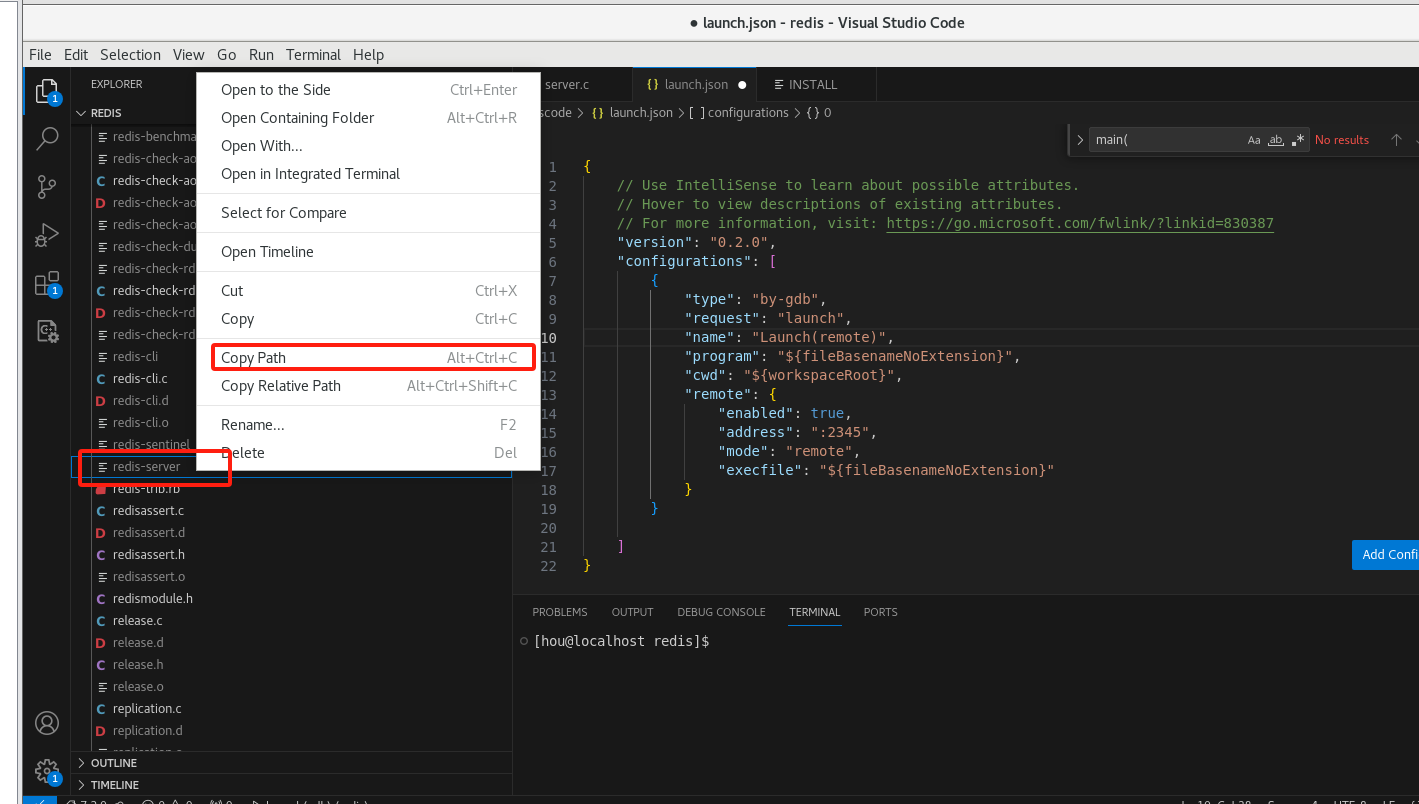
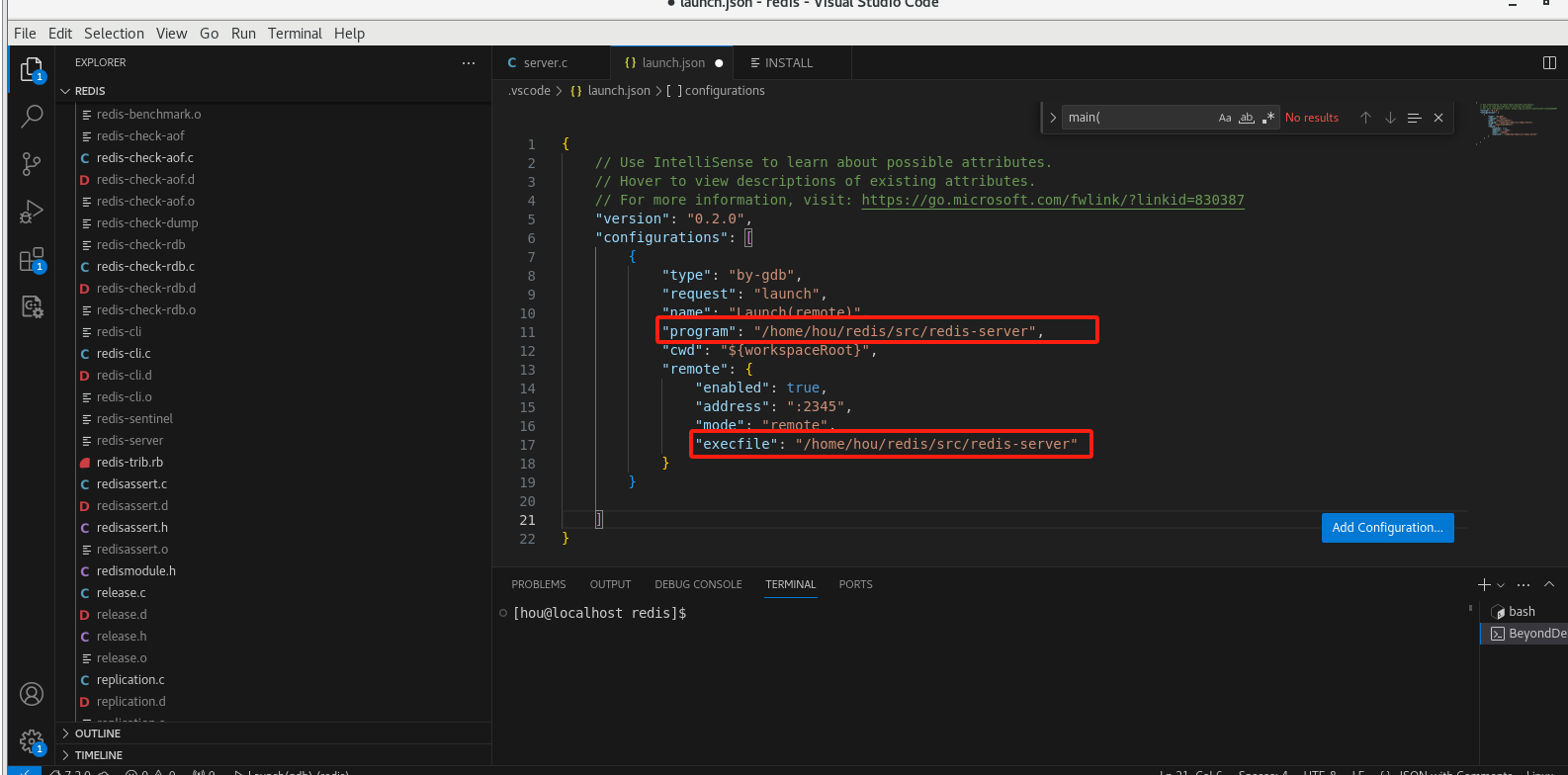
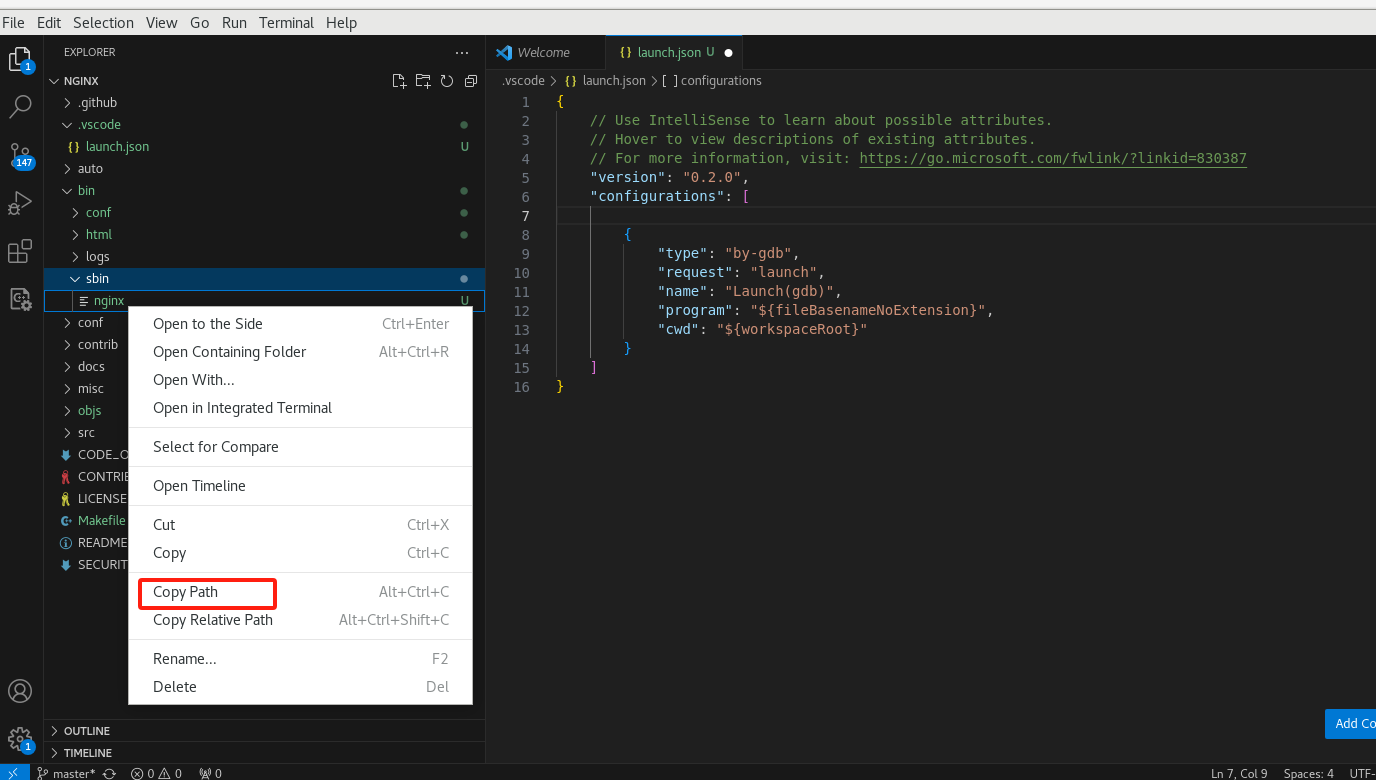
修改执行路径
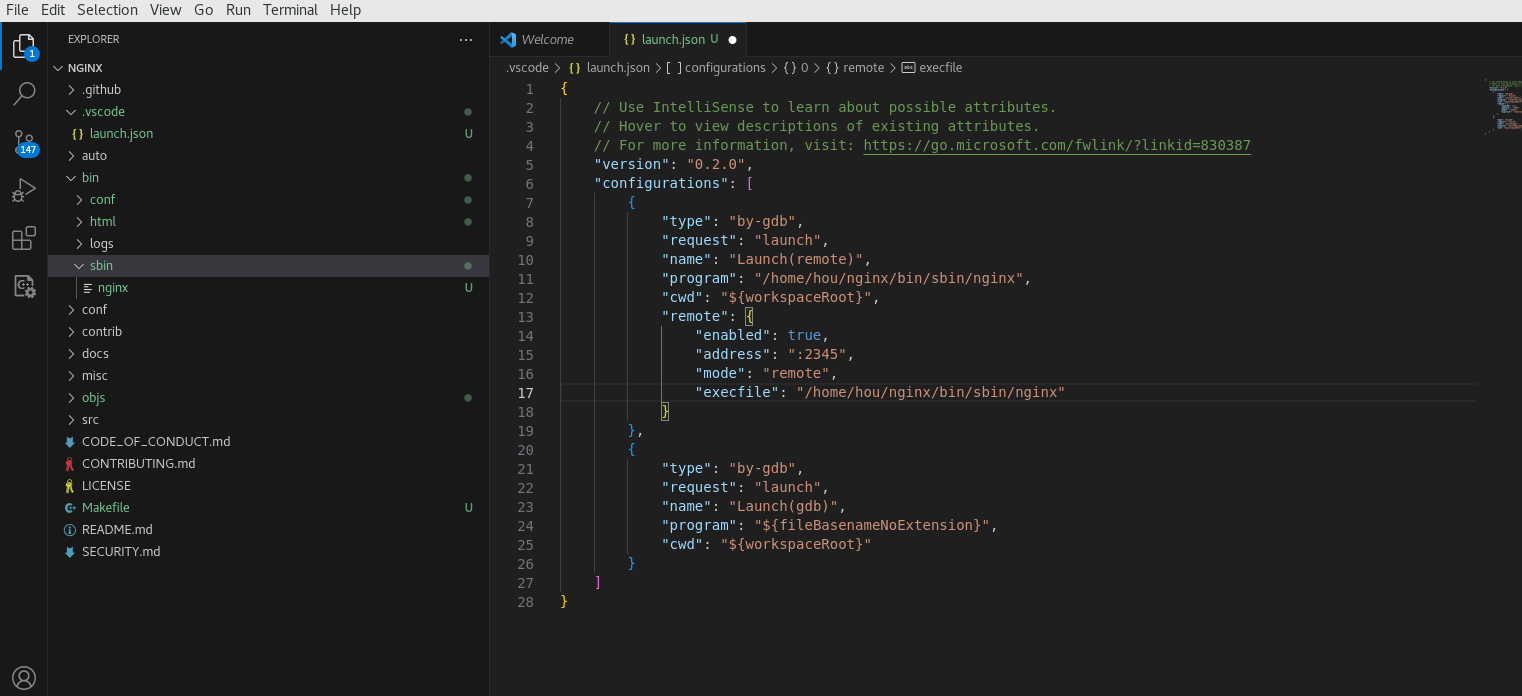
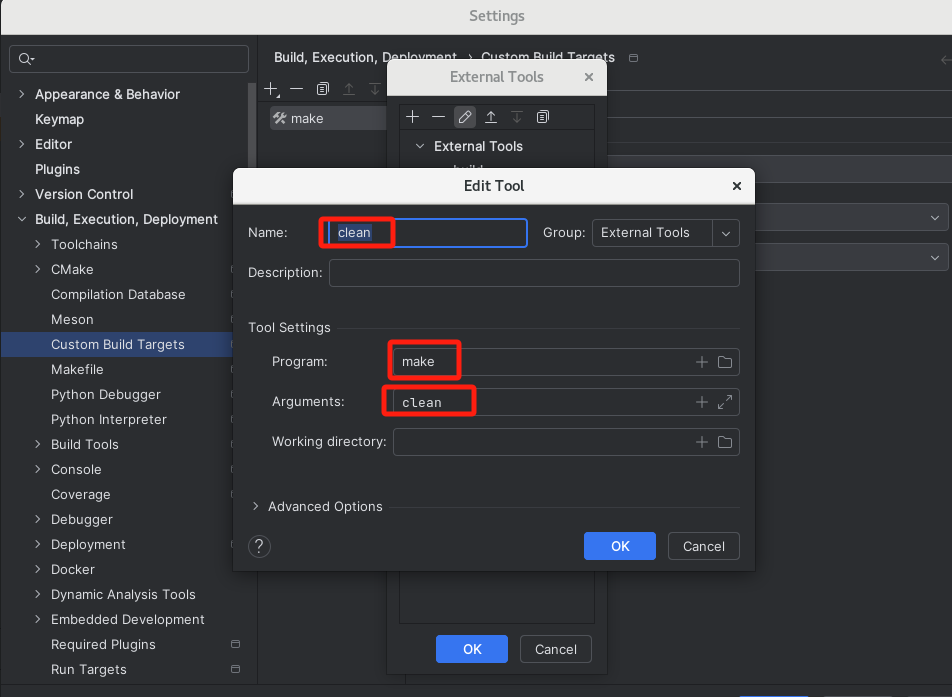
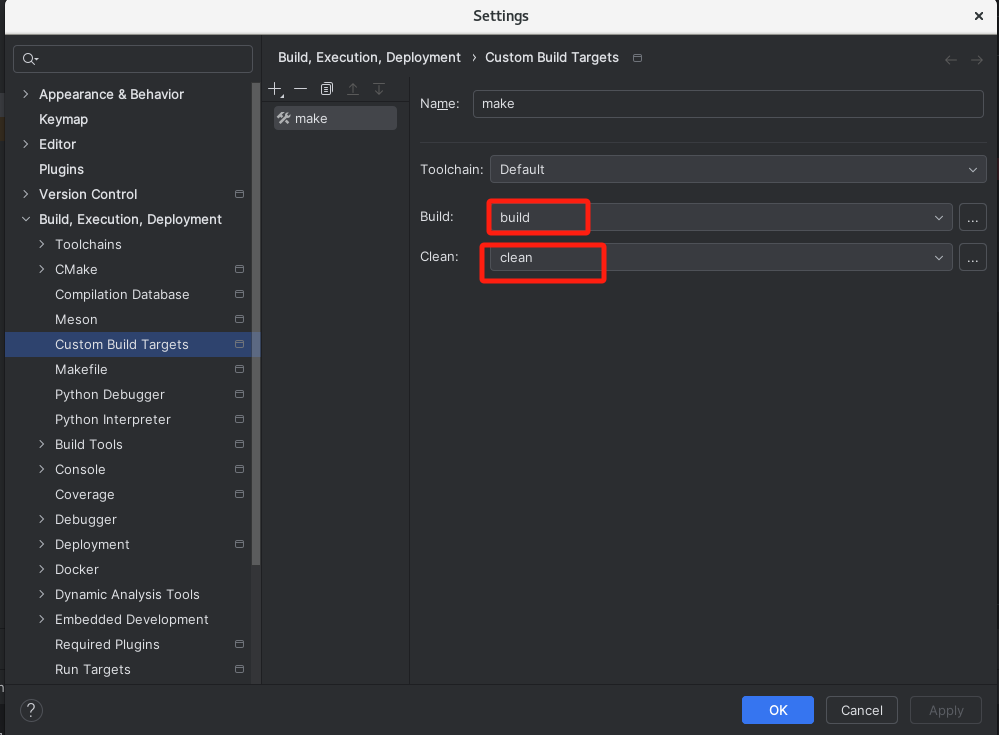
配置launch.json如下
1 | { |
安装gdbserver
1 | sudo yum install gdb-gdbserver |
进入nginx执行目录
1 | cd /home/hou/nginx/bin/sbin |

执行远程调试服务命令
1 | gdbserver :2345 nginx -v |
看到服务器已经在监听了

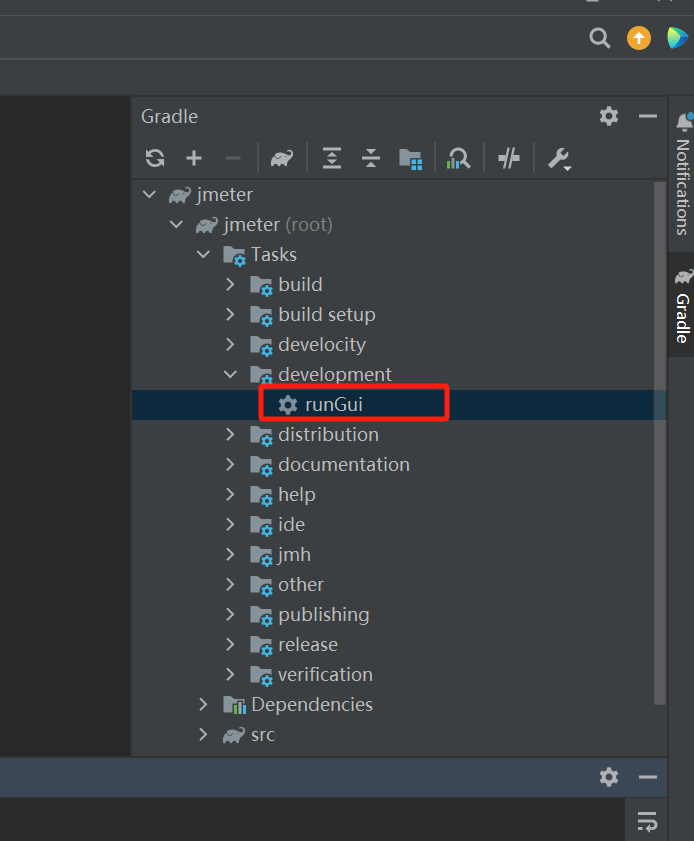
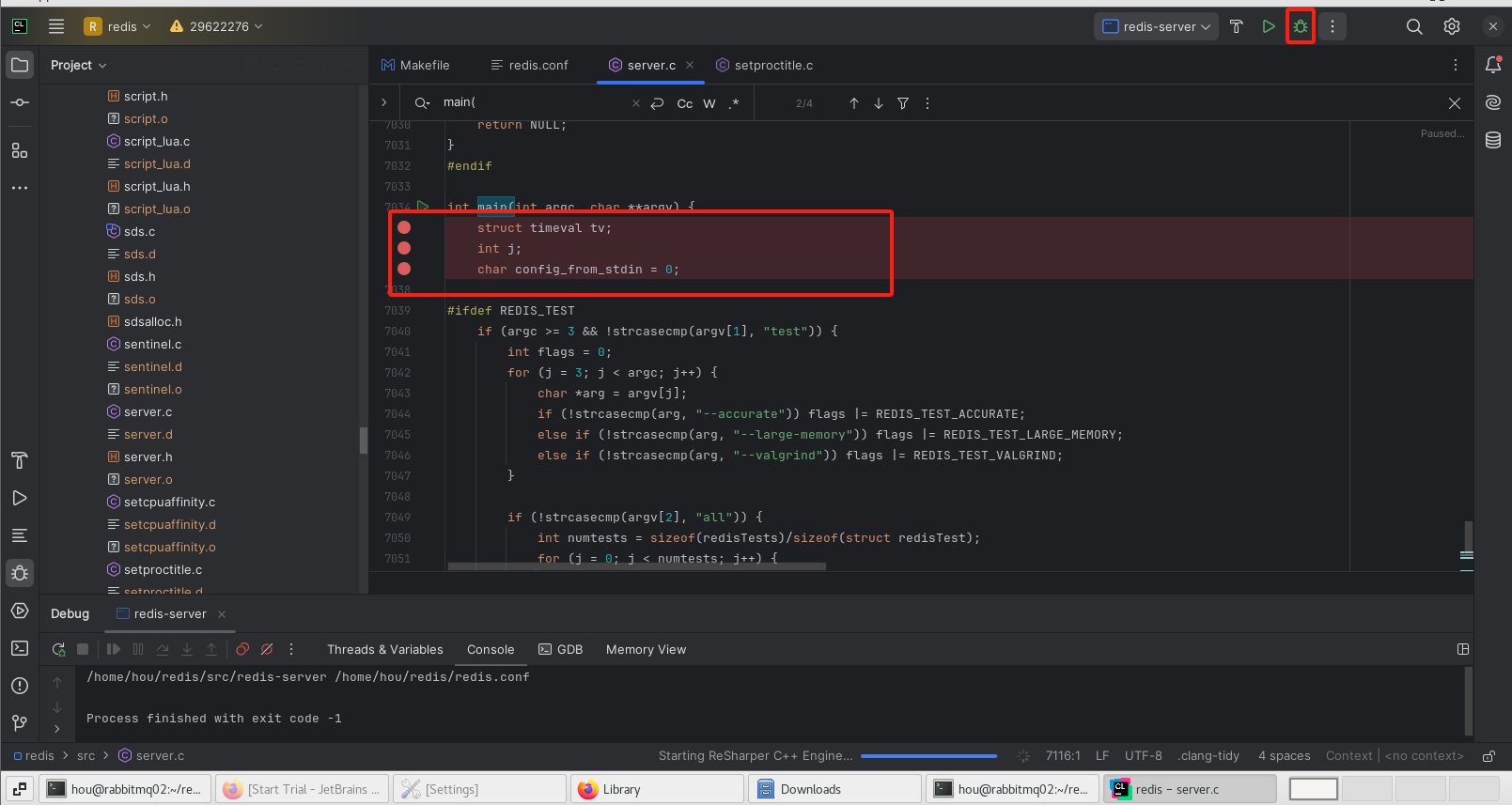
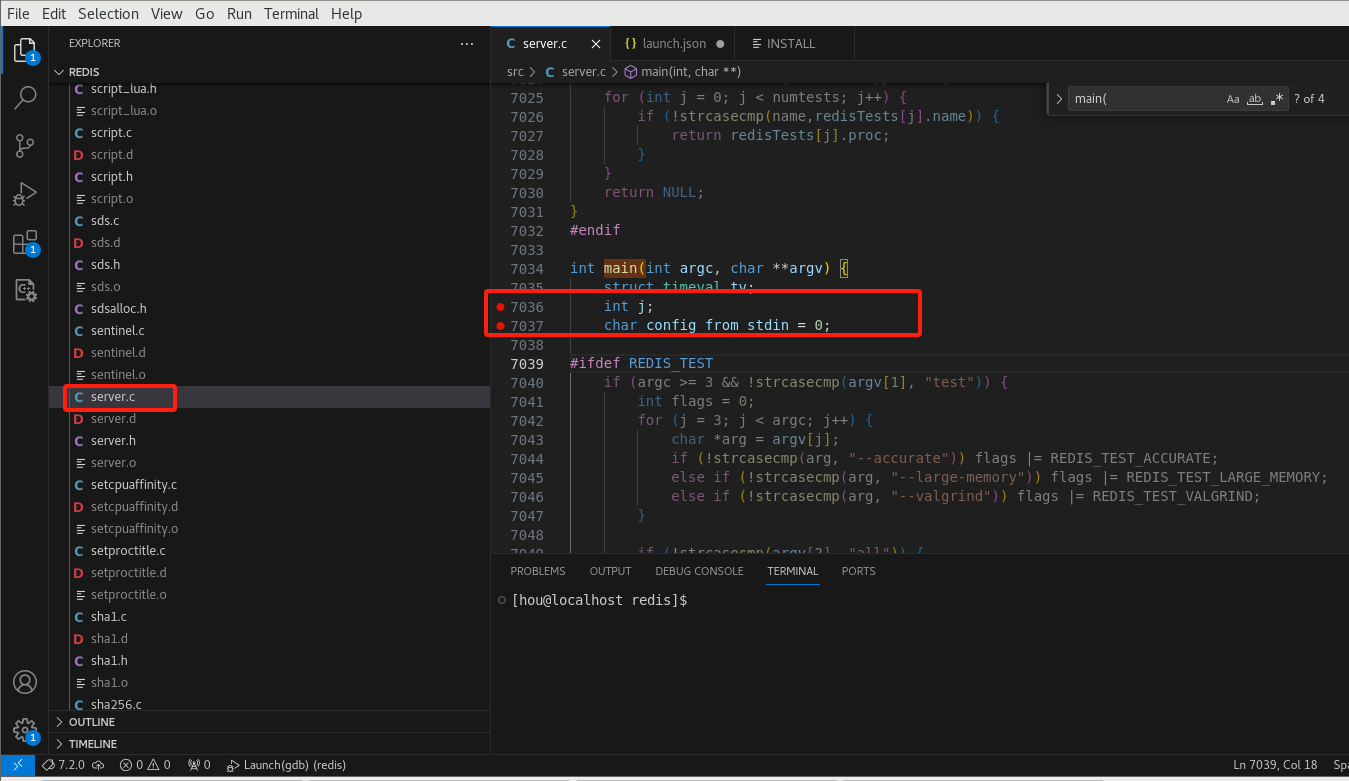
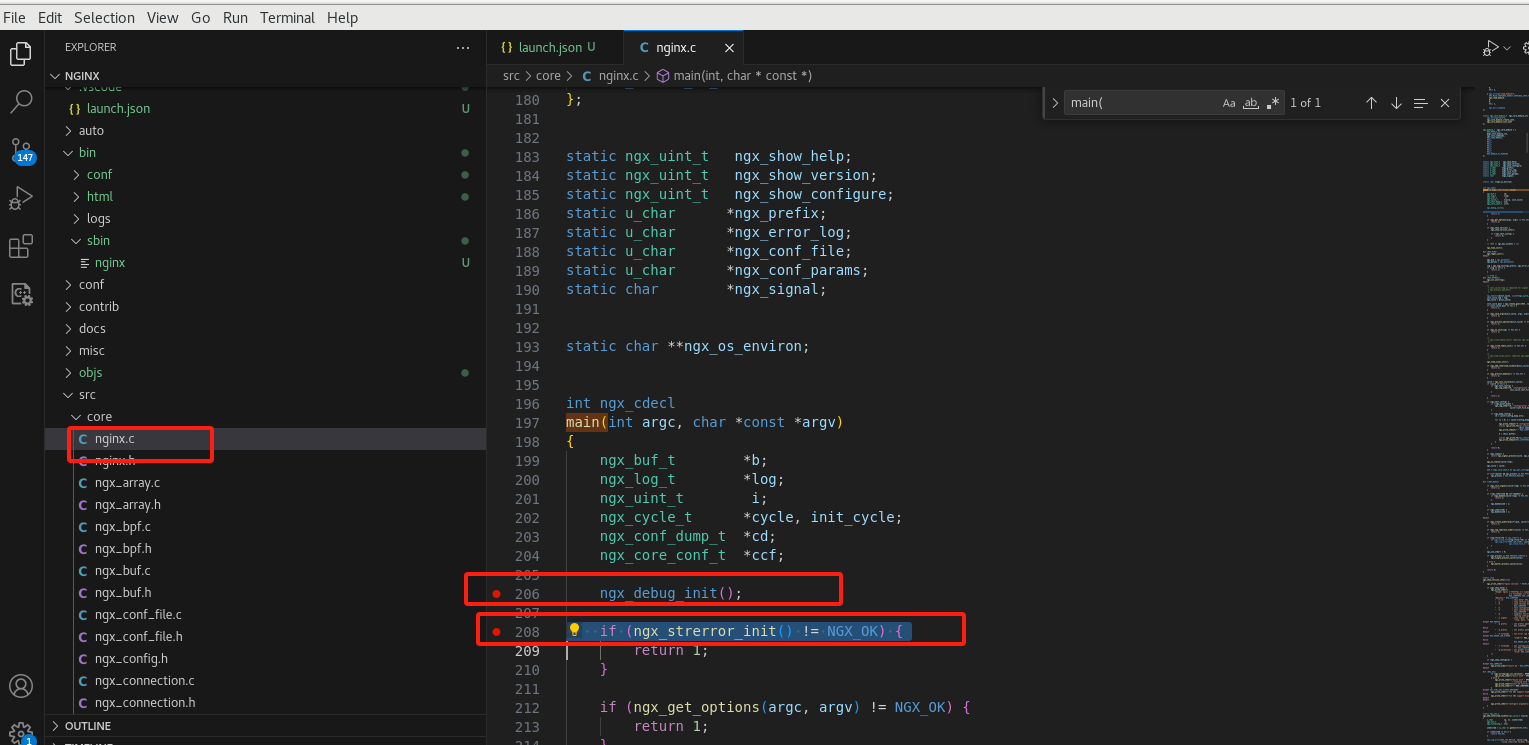
设置断点
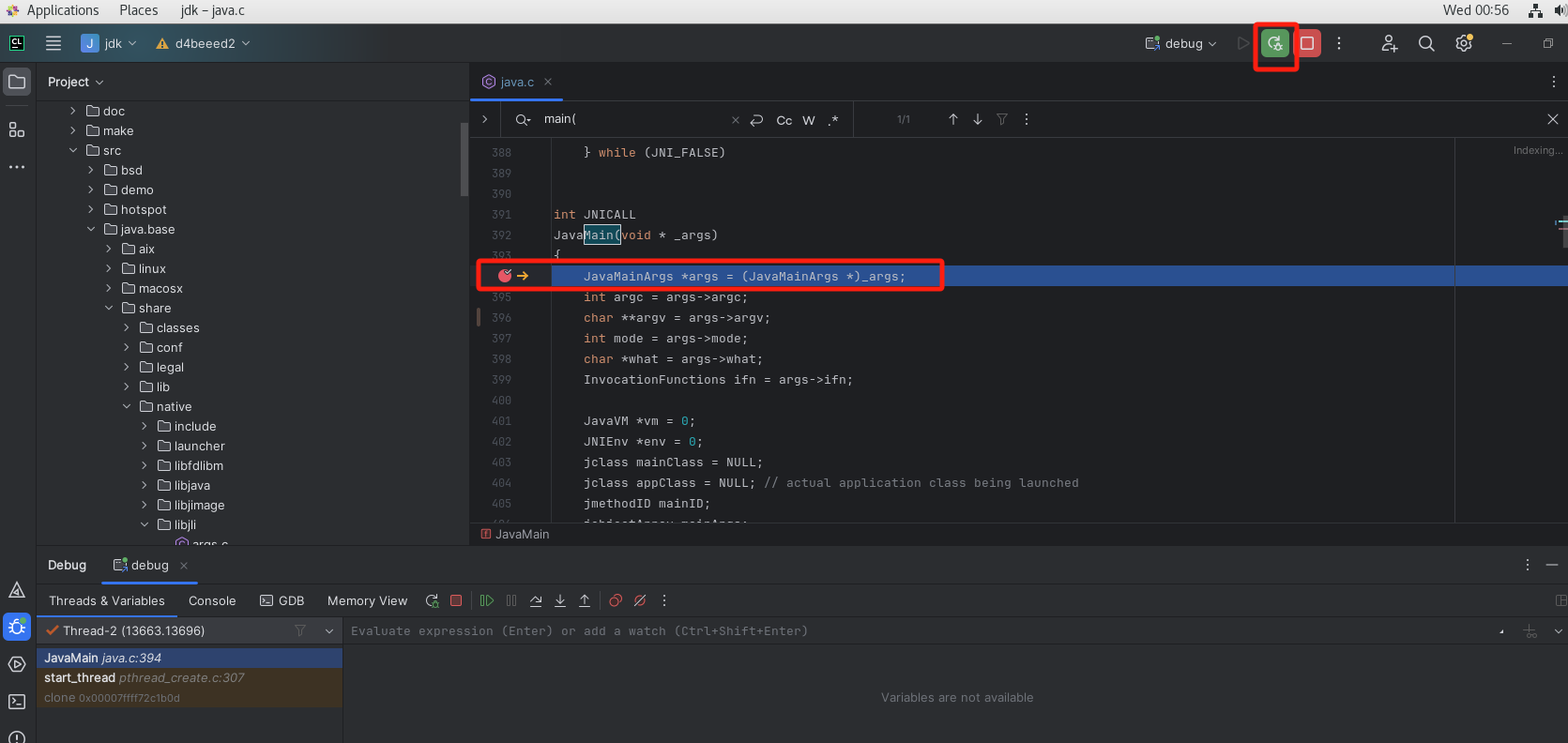
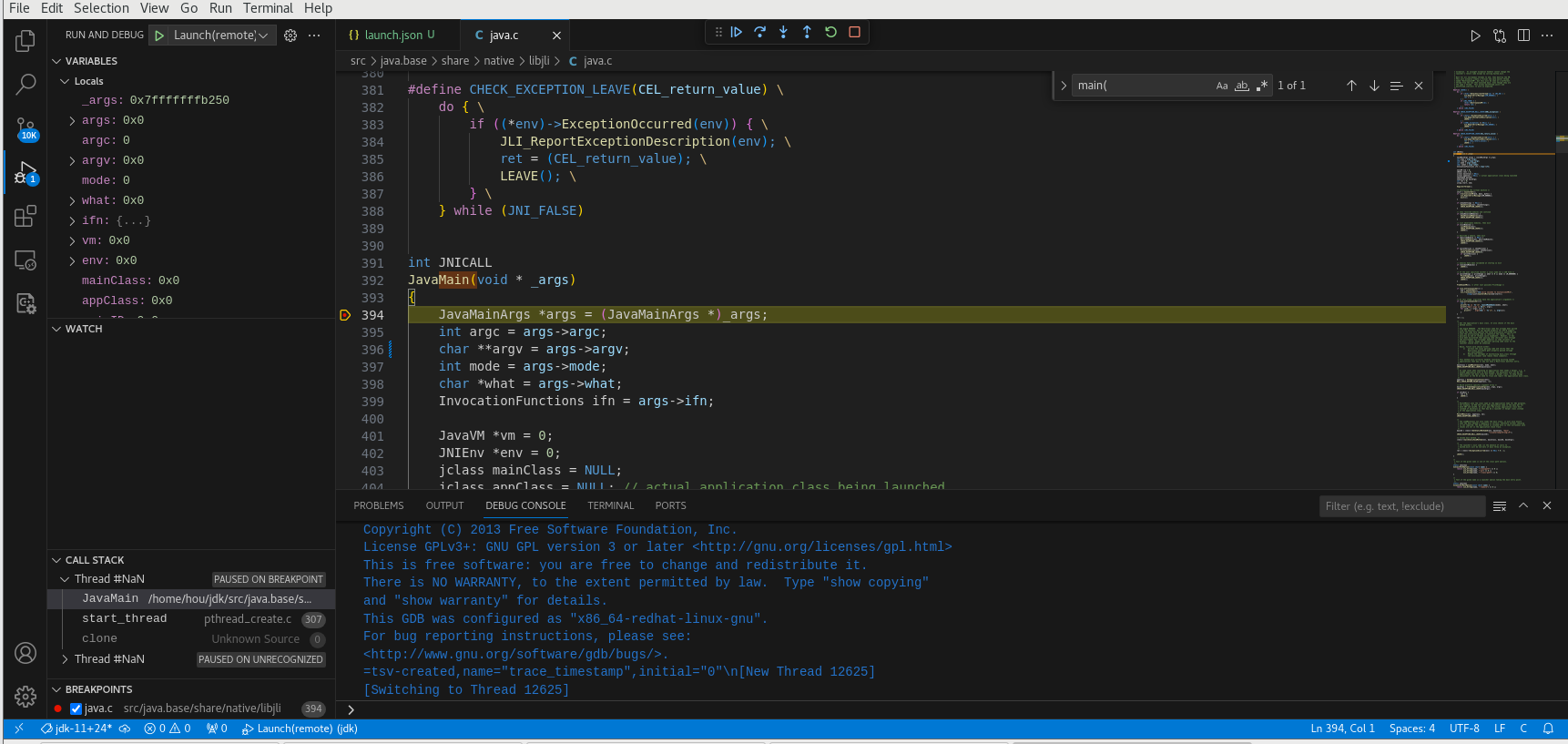
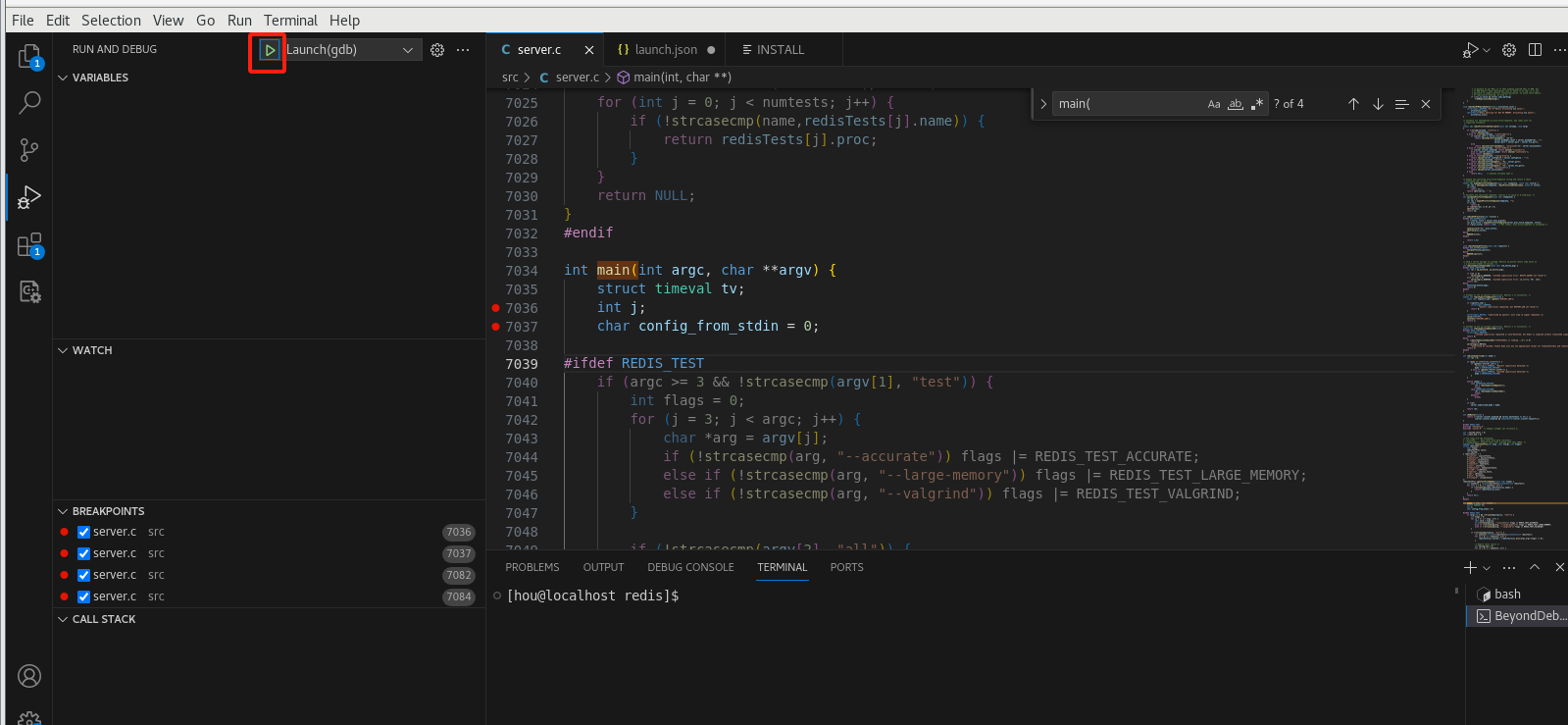
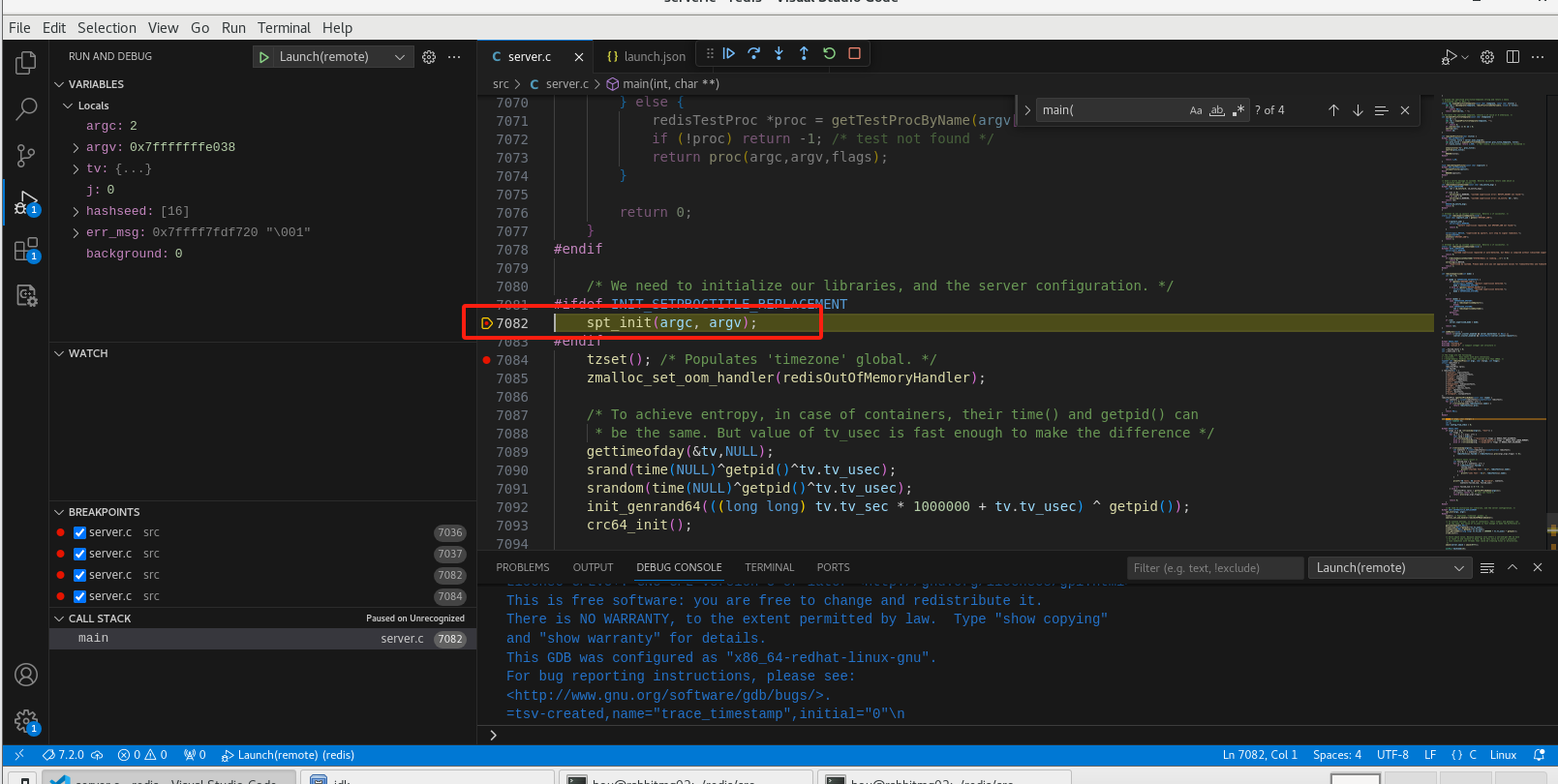
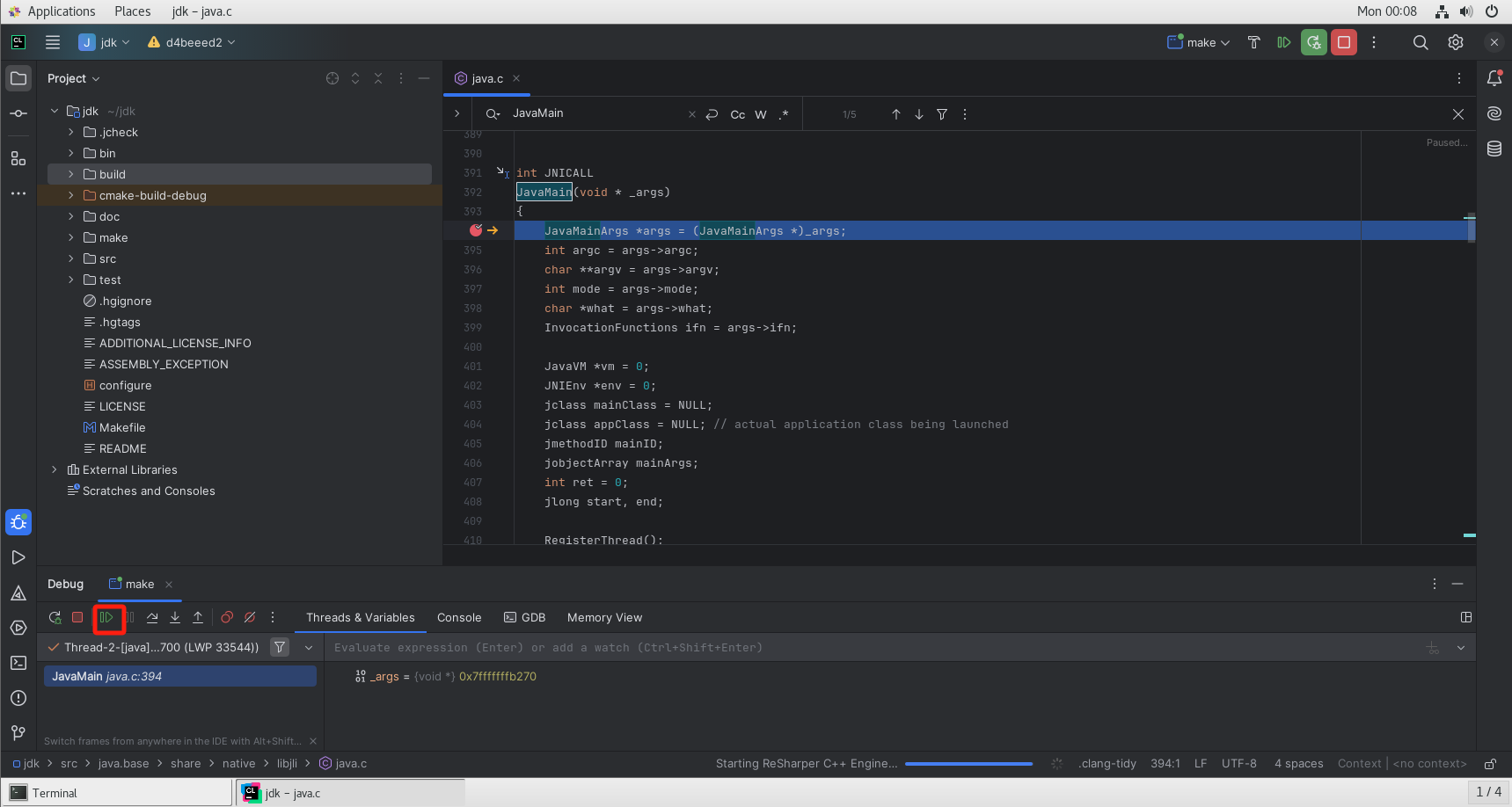
调试
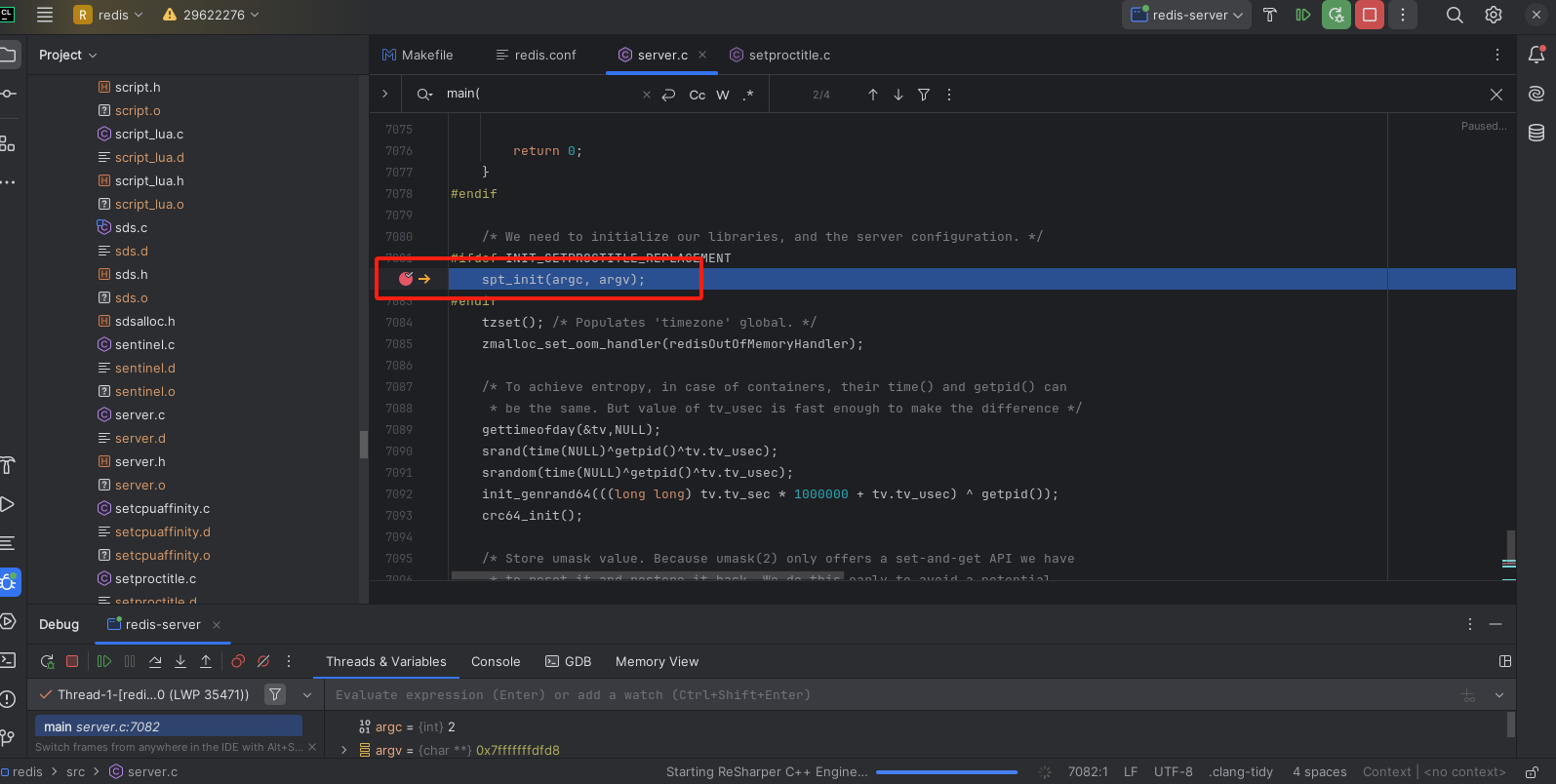
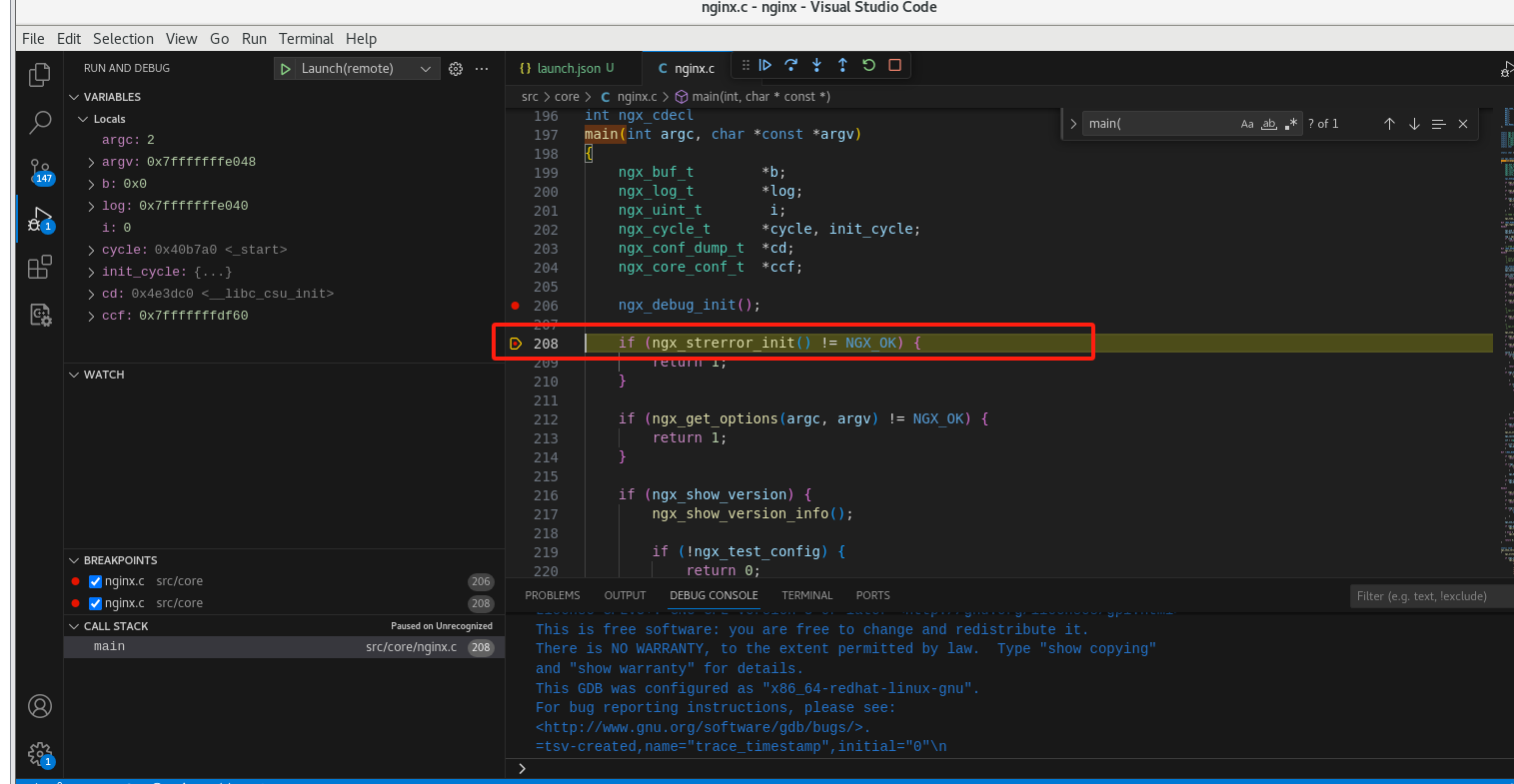
执行调试
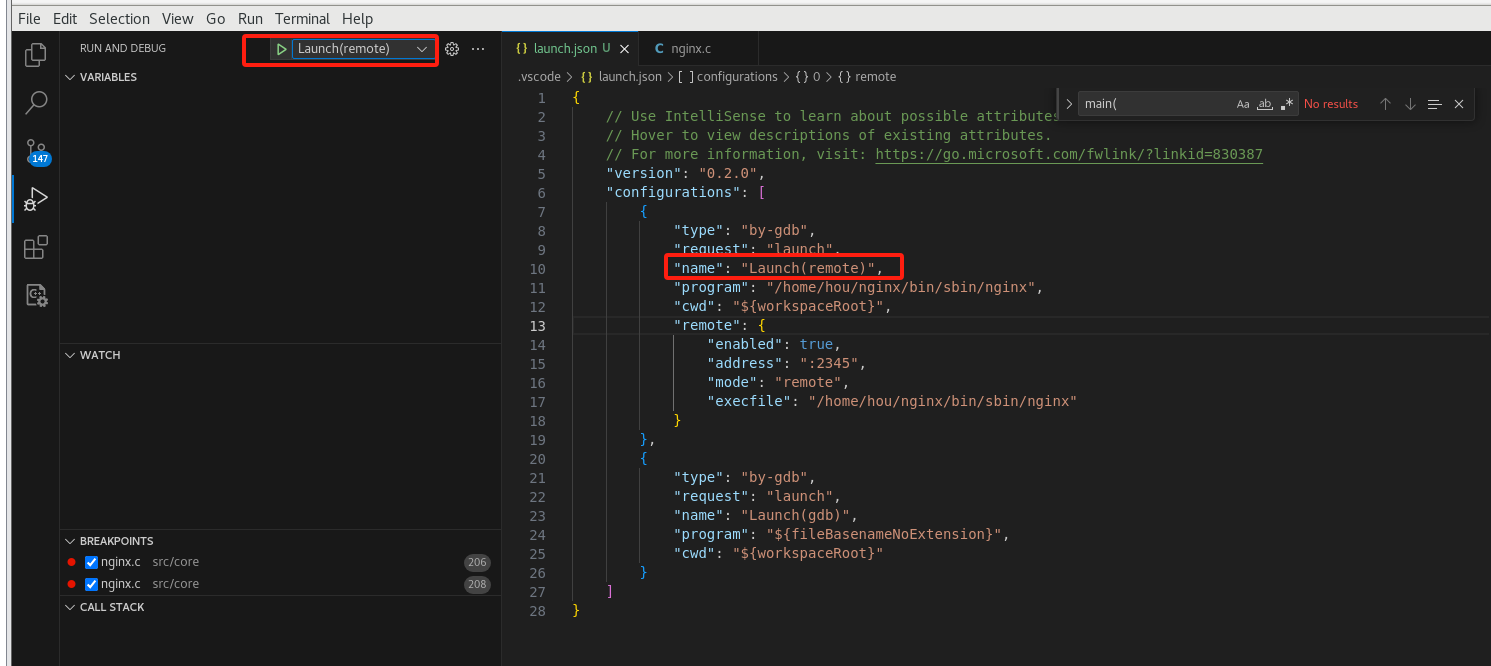
可以看到已经执行到断点处
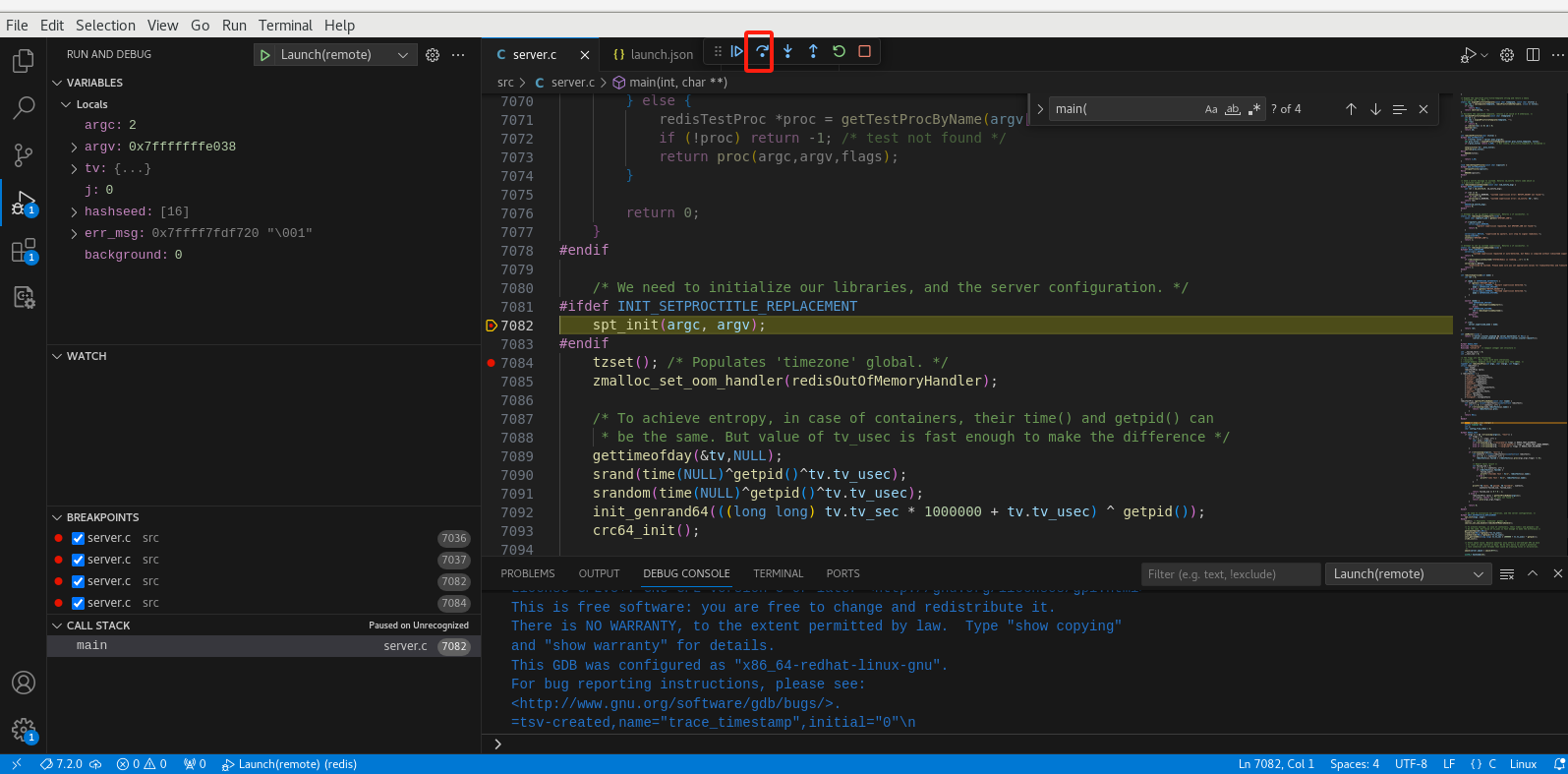
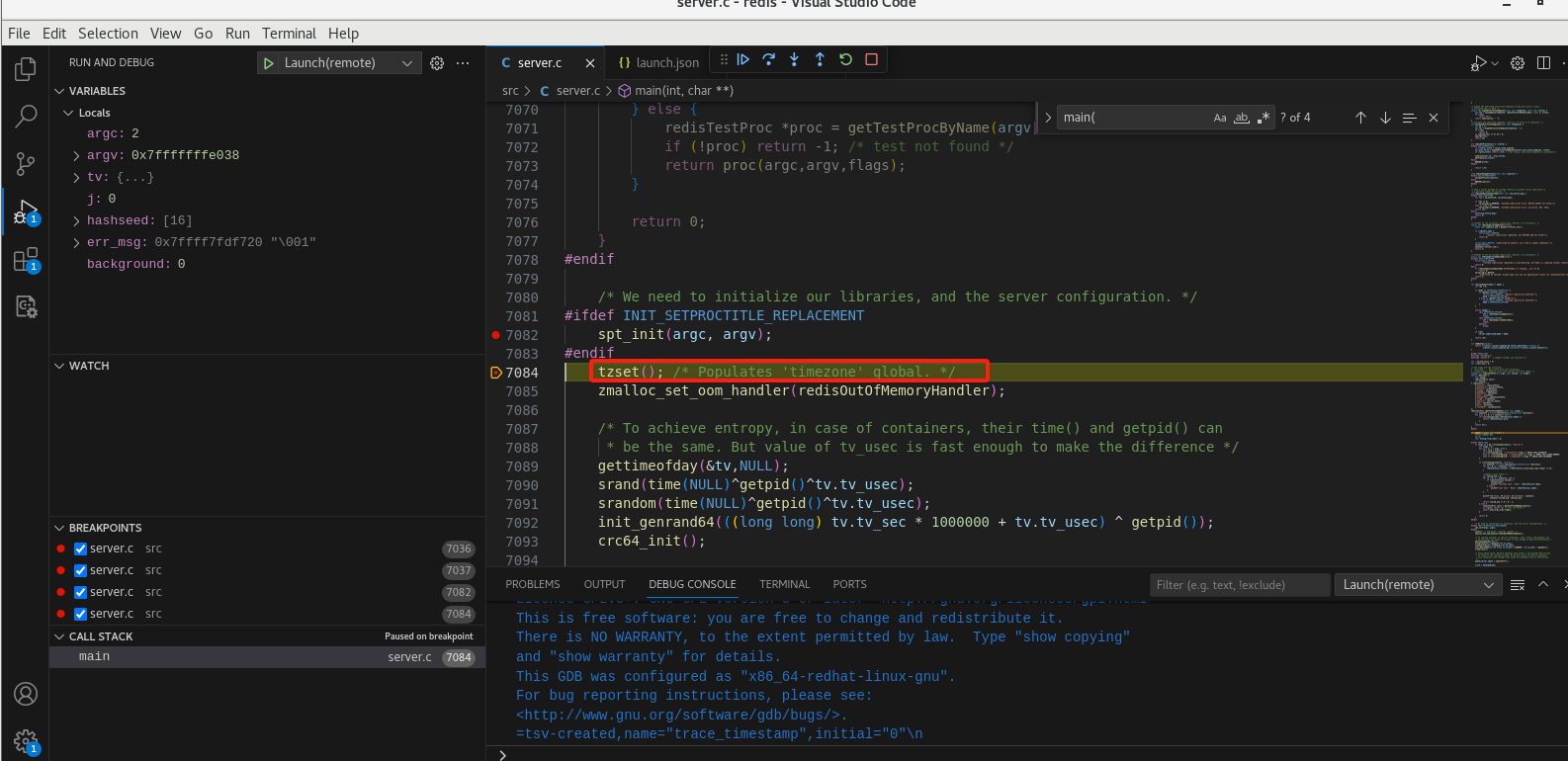
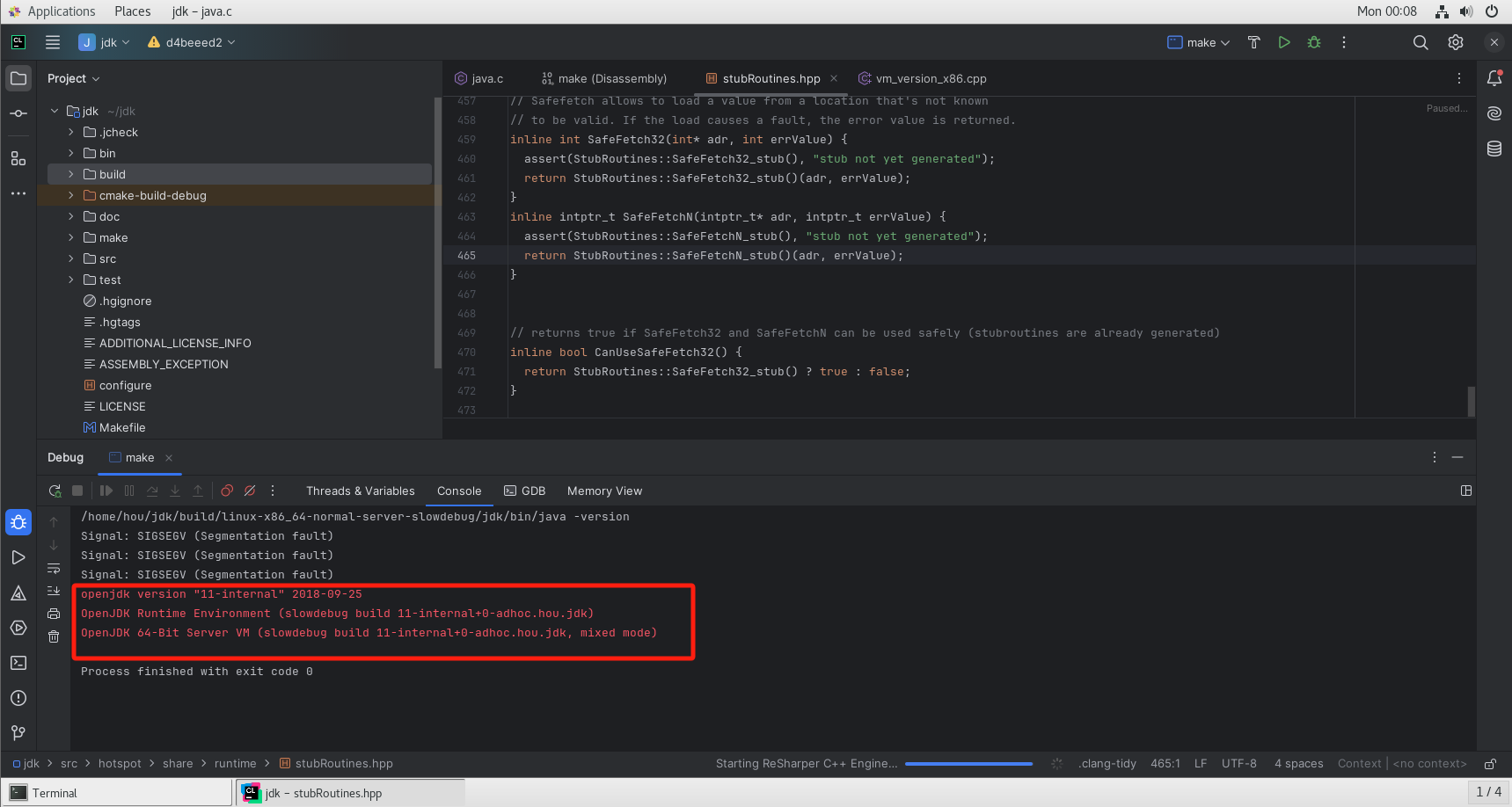
点击单步调试
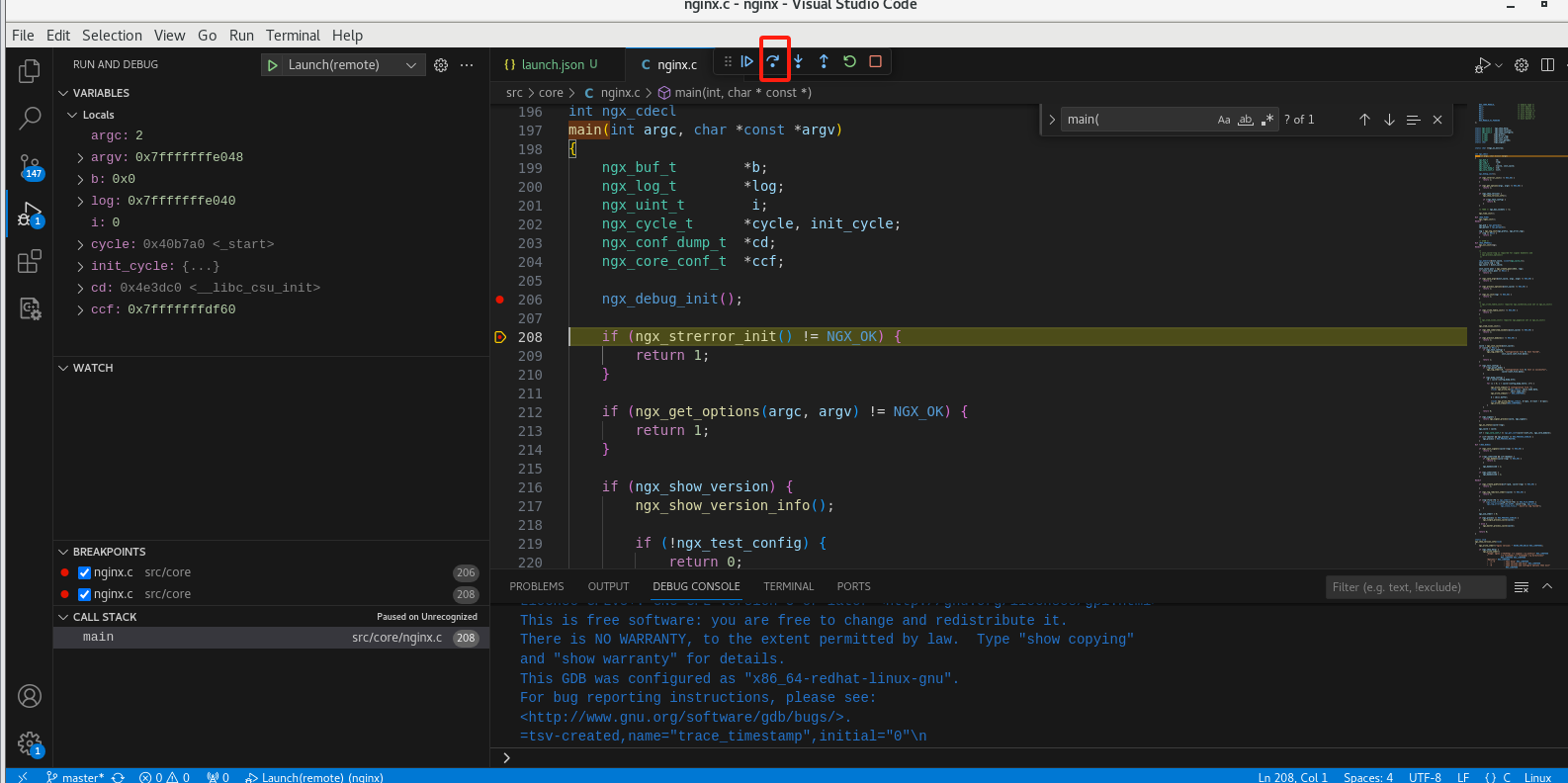
可以看到执行到下一步了